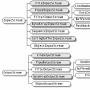
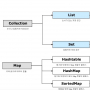
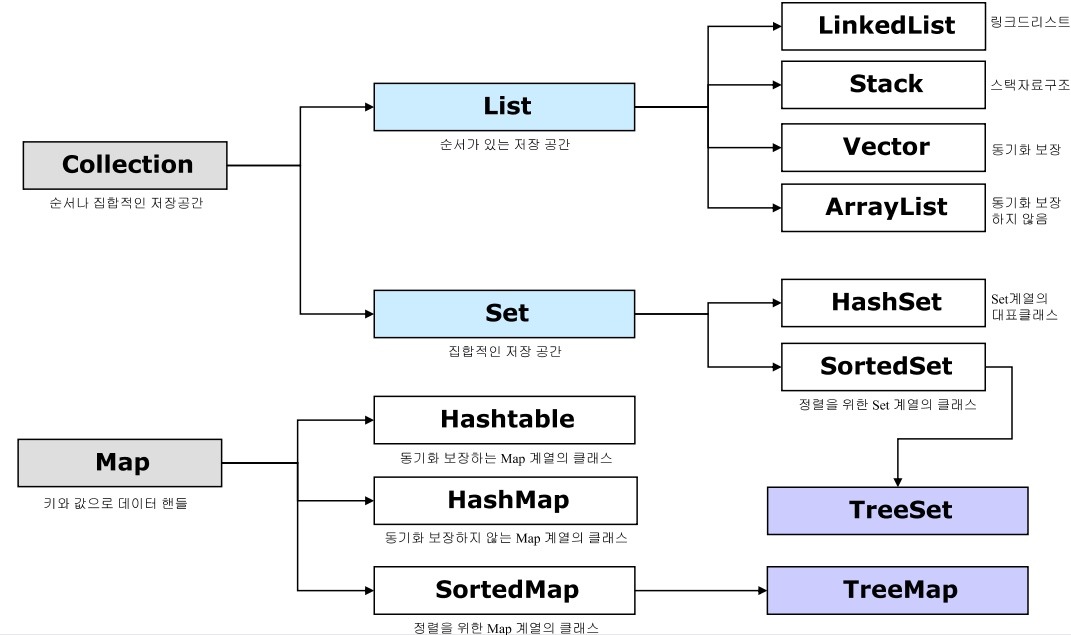
컬렉션 프레임워크
인터페이스 | 특 징 |
List | 순서가 있는 데이터의 집합, 데이터의 중복을 허용한다. --> 데이터를 add하면 앞에서 부터 순차적(순서대로)으로 데이터가 들어간다. 그래서 각각의 저장되어 있는 공간들은 고유한 index를 갖는다. ex.) 대기자 명단 |
구현 클래스: ArrayList, LinkedList, Stack, Vector등
| |
Set | 순서를 유지하지 않는 데이터의 집합, 데이터의 중복을 허용하지 않는다. --> 집합이다. 데이터가 순서와는 상관없이 add된다. 중복되지 않는다. ex.) 양의 정수 집합, 소수의 집합 |
구현 클래스: HashSet, TreeSet등 | |
Map | 키와 값의 쌍으로 이루어진 데이터의 집합. 순서는 유지되지 않으며, 키는 중복을 허용하지 않고, 값을 중복을 허용한다. ex.) 우편번호, 지역번호 |
구현 클래스: HashMap, TreeMap, Hashtable, Properties등 |
1. 컬렉션 프레임워크란
컬렉션즈 프래임워크라는 것은 다른 말로는 컨테이너라고도 부른다. 즉 값을 담는 그릇이라는 의미이다. 그런데 그 값의 성격에 따라서 컨테이너의 성격이 조금씩 달라진다. 자바에서는 다양한 상황에서 사용할 수 있는 다양한 컨테이너를 제공하는데 이것을 컬렉션즈 프래임워크라고 부른다. ArrayList는 그중의 하나다.
2. 배열과 비교
배열은 연관된 데이터를 관리하기 위한 수단이었다. 그런데 배열에는 몇가지 불편한 점이 있었는데 그 중의 하나가 한번 정해진 배열의 크기를 변경할 수 없다는 점이다.(배열을 만들고 나서 추후에 배열의 크기를 바꿀수 없다.) 이러한 불편함을 컬렉션즈 프래임워크를 사용하면 줄어든다.
import java.util.ArrayList;
public class ArrayListDemo {
public static void main(String[] args) {
String[] arrayObj = new String[2];
// 배열의 크기 지정--> 생성후 변경 불가
arrayObj[0] = "one";
arrayObj[1] = "two";
// arrayObj[2] = "three"; 오류가 발생한다.
// --> 배열의 크기 변경 불가 (배열은 배열의 크기를 알 때만 사용할 수 있다.)
for(int i=0; i<arrayObj.length; i++){
System.out.println(arrayObj[i]);
}
ArrayList<String> al = new ArrayList<String>(); // <Strinf>: al 참조변수에 추가되는 값이 String 데이터 타입이라는 것을 지정한다.
// 배열과 비슷하나, 객체 생성후 몇개의 값을 사용할 지 지정할 필요가 없다.
// --> 여기서 al 참조변수는 컨테이너라고 한다.(자료를 담는 그릇이 된다.) --> 아래의 코드는 add()를 이용하여 al에 one, two, Three를 넣은 모습이다.
al.add("one");
al.add("two");
al.add("three");
// 값을 추가해도 상관없다. outofbound 에러 없음
for(int i=0; i<al.size(); i++){// 배열은 length
// String value = al.get(i);// value 변수에 리턴되는 데이터타입은 ArrayList이므로 String으로 데이터타입 지정시 에러가 발생한다.
// 그래서 (String)al.get(i) 또는 ArrayList<String>을 객체 선언시 지정해야 한다.
System.out.println(al.get(i));//i=1이면 one, i=2이면 two, 제네릭을 통해서 (String)al.get(i)을 통해 형변환할 필요가 없다.
}
}
}
실행결과)
one
two
one
two
three
- ArrayList는 배열과는 사용방법이 조금 다르다. 배열의 경우 값의 개수를 구할 때 .length를 사용했지만 ArrayList는 메소드 size를 사용한다.
또한, 특정한 값을 가져올 때 배열은 [인덱스 번호]를 사용했지만 컬렉션은 .get(인덱스 번호)를 사용한다.
3. 중복을 허용하는 List/ 중복 허용하지 않는 Set
자료를 꺼낼때 순서가 유지되는지 아닌지 주의있는 보자
import java.util.ArrayList;
import java.util.HashSet;
import java.util.Iterator;
public class ListSetDemo {
public static void main(String[] args) {
ArrayList<String> al = new ArrayList<String>();
al.add("one");
al.add("two");
al.add("two");
al.add("three");
al.add("three");
al.add("five");
System.out.println("array");
Iterator<String> ai = al.iterator(); //<String>에서 제네릭을 선언하지 않았다면 (String)로 형변환을 해야 한다.
while(ai.hasNext()){
System.out.println(ai.next());
}
HashSet<String> hs = new HashSet<String>();
hs.add("one");
hs.add("two");
hs.add("two");
hs.add("three");
hs.add("three");
hs.add("five");
Iterator<String> hi = hs.iterator();
System.out.println("\nhashset");
while(hi.hasNext()){
System.out.println(hi.next());
}
}
}
실행결과)
array
one
two
two
three
three
five
hashset
two
five
one
three
4. Map
(1) 예제 1
import java.util.*;
public class MapDemo {
public static void main(String[] args) {
HashMap<String, Integer> a = new HashMap<String, Integer>();
a.put("one", 1);// key, value
a.put("two", 2);
a.put("three", 3);
a.put("four", 4);
System.out.println(a.get("one"));
System.out.println(a.get("two"));
System.out.println(a.get("three"));
iteratorUsingForEach(a);
iteratorUsingIterator(a);
}
// Map 데이터 iterator 기능 없음 --> Map 데이터 가져오는 방법 1
static void iteratorUsingForEach(HashMap<String, Integer> map){
Set<Map.Entry<String, Integer>> entries = map.entrySet();
for (Map.Entry<String, Integer> entry : entries) {
System.out.println(entry.getKey() + " : " + entry.getValue());
//Map 데이터를 가져오는 방법 --> getKey()=key값 ,getValue()=value값
}
}
// Map 데이터 iterator 기능 없음 --> Map 데이터 가져오는 방법 2
static void iteratorUsingIterator(HashMap<String, Integer> map){
Set<Map.Entry<String, Integer>> entries = map.entrySet();
Iterator<Map.Entry<String, Integer>> i = entries.iterator();
while(i.hasNext()){
Map.Entry<String, Integer> entry = i.next();
System.out.println(entry.getKey()+" : "+entry.getValue());
}
}
}
(2) 예제2
import java.util.*;
class GenericsEx5
{
public static void main(String[] args)
{
HashMap<String,Student> map = new HashMap<String,Student>();
map.put("1-1", new Student("자바왕",1,1,100,100,100));
map.put("1-2", new Student("자바짱",1,2,90,80,70));
map.put("2-1", new Student("홍길동",2,1,70,70,70));
map.put("2-2", new Student("전우치",2,2,90,90,90));
Student s1 = map.get("1-1");
System.out.println("1-1 :" + s1.name);
Iterator<String> itKey = map.keySet().iterator();
// key값만 가져오는 경우
while(itKey.hasNext()) {
System.out.println(itKey.next());
}
Iterator<Student> itValue = map.values().iterator();
int totalSum = 0;
// value값만 가져오는 경우
while(itValue.hasNext()) {
Student s = itValue.next();
System.out.println(s);
totalSum += s.total;
}
System.out.println("전체 총점:"+totalSum);
} // main
}
class Student extends Person implements Comparable<Person> {
String name = "";
int ban = 0;
int no = 0;
int koreanScore = 0;
int mathScore = 0;
int englishScore = 0;
int total = 0;
Student(String name, int ban, int no, int koreanScore, int mathScore, int englishScore) {
super(ban+"-"+no, name);
this.name = name;
this.ban = ban;
this.no = no;
this.koreanScore = koreanScore;
this.mathScore = mathScore;
this.englishScore = englishScore;
total = koreanScore + mathScore + englishScore;
}
public String toString() {
return name + "\t"
+ ban + "\t"
+ no + "\t"
+ koreanScore + "\t"
+ mathScore + "\t"
+ englishScore + "\t"
+ total + "\t";
}
// Comparable<Person>이므로 Person타입의 매개변수를 선언.
public int compareTo(Person o) {
return id.compareTo(o.id); // String클래스의 compareTo()를 호출
}
} // end of class Student
class Person {
String id;
String name;
Person(String id, String name) {
this.id = id;
this.name = name;
}
}
5. Iterator
컬렉션 프레임워크에서 컬렉션에 저장된 요소들을 읽어오는 방법을 표준화 하였다. 컬렉션에 저장된 각 요소에 접근하는 기능을 가진 Iterator인터페이스를 정의하고, Collection인터페이스에는 Iterator
(Iterator를 구현한 클래스의 인스턴스)를 반환하는 iterator()를 정의하고 있다.
public interface Iterator{
boolean hasNext();
Object next();
void remove();
}
public interface Collection{
...
public Iterator iterator();
...
}
iterator()는 Collection인터페이스에 정의된 메서드이므로 Collection인터페이스의 자손인 List와 Set에도 포함되어 있다.
그래서 List나 Set인터페이스를 구현하는 컬렉션은 iterator()가 각 컬렉션의 특징에 알맞게 작성되어 있다.

List list = new ArrayList();
Iterator it = list.iterator();
while(it.hasNext()){
System.out.println(it.next());
}
ArrayList에 저장된 요소들은 출력하기 위한 코드이다.
ArrayList대신 List인터페이스를 구현한 다른 컬렉션 클래스에 대해서도 이와 동일한 코드를 사용할 수 있다. 첫 줄에서 ArrayList 대신 List인터페이스를 구현한 다른 컬렉션 클래스의 객체를 생성하도록 변경하기만 하면 된다.
Map map = new HashMap();
...
Iterator it = map.keySet().iterator();
Map 인터페이스를 구현한 컬렉션 클래스는 키와 값을 쌍을 저장하고 있기 때문에 iterator()를 직접 호출할 수 없고, 그 대신 ketSet()이나 entrySet()과 같은 메서드를 통해서 키와 값을 각각 따로 Set의 형태로 얻어 온 후에 다시 iterator()를 호출해야 Iterator를 얻을 수 있다.
(1) 예제1
import java.util.*;
class IteratorEx1{
public static void main(String[] args) {
ArrayList list = new ArrayList();
list.add("1");
list.add("2");
list.add("3");
list.add("4");
list.add("5");
Iterator it = list.iterator();
while(it.hasNext()) {
Object obj = it.next();
System.out.println(obj);
}
} // main
} // class
실행 결과)
1
2
3
4
5
List 클래스들은 저장순서를 유지하기 때문에 Iterator를 이용해서 읽어 온 결과 역시 저장 순서와 동일하지만 Set클래스들은 각 요소간의 순서가 유지 되지 않기 때문에 Iterator를 이용해서 저장된 요소들은 읽어와도 처음에 저장된 순서와 같지 않다.
6. 정렬
import java.util.*;
class ArrayListEx1
{
public static void main(String[] args)
{
ArrayList<Integer> list1 = new ArrayList<Integer>(10);
list1.add(new Integer(5));
list1.add(new Integer(4));
list1.add(new Integer(2));
list1.add(new Integer(0));
list1.add(new Integer(1));
list1.add(new Integer(3));
ArrayList list2 = new ArrayList(list1.subList(1,4));
print(list1, list2);
Collections.sort(list1); // list1과 list2를 정렬한다.
Collections.sort(list2); // Collections.sort(List l)
print(list1, list2);
System.out.println("list1.containsAll(list2):"+ list1.containsAll(list2));
list2.add("B");
list2.add("C");
list2.add(3, "A");
print(list1, list2);
list2.set(3, "AA");
print(list1, list2);
// list1에서 list2와 겹치는 부분만 남기고 나머지는 삭제한다.
System.out.println("list1.retainAll(list2):" + list1.retainAll(list2));
print(list1, list2);
// list2에서 list1에 포함된 객체들을 삭제한다.
for(int i= list2.size()-1; i >= 0; i--) {
//--> for문의 카운터를 0부터 증가시킨 것이 아니라, list2.size()-1 부터 감소시키면서 거꾸로 반복시켰다.
//만약 카운터를 증가시켜가면서 삭제하면 한 요소가 삭제될 때마다 빈 공간을 채우기 위해 나머지 요소들이 자리이동을 하기 때문에 올바른 결과를 얻을 수 없다. 그래서 카운터를 감소시켜가면서
//삭제를 해야 자리이동이 발생해도 영향을 받지 않고 작업이 가능하다.
if(list1.contains(list2.get(i)))
list2.remove(i);
}
print(list1, list2);
} // main
static void print(ArrayList list1, ArrayList list2) {
System.out.println("list1:"+list1);
System.out.println("list2:"+list2);
System.out.println();
}
} // class
실행 결과)
list1:[5, 4, 2, 0, 1, 3]
list2:[4, 2, 0]
list1:[0, 1, 2, 3, 4, 5] // Collections.sort(List1)을 이용해서 정렬하였다.(Collections는 클래스이다.)
list2:[0, 2, 4]
list1.containsAll(list2):true // list1이 list2의 모든 요소를 포함하고 있는 경우에만 true를 얻는다.
list1:[0, 1, 2, 3, 4, 5]
list2:[0, 2, 4, A, B, C]// add(Object obj)를 이용해서 새로운 객체를 저장하였다.
list1:[0, 1, 2, 3, 4, 5]
list2:[0, 2, 4, AA, B, C]// set(int index, Object obj)를 이용해서 저장된 객체를 변경하였다.
list1.retainAll(list2):true// retainAll의 작업결과로 list1에 변화가 있었으므로 true를 반환한다.
list1:[0, 2, 4]// list2와의 공통 요소 이외에는 모두 삭제되었다.(변화가 있었다.)
list2:[0, 2, 4, AA, B, C]
list1:[0, 2, 4]
list2:[AA, B, C]
 제네릭
제네릭