쓰레드 기본
1. 프로세스와 쓰레드
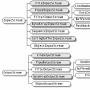
프로세스란 간단히 말해서 '실행 중인 프로그램'이다. 프로그램을 실행하면 OS로부터 실행에 필요한 자원(메모리)을 할당받아 프로세스가 된다.
프로그램 ---------------실행---------------> 프로세스
프로세스는 프로그램을 수행하는 데 필요한 데이터와 메모리 등의 자원 그리고 쓰레드로 구성되어 있으며 프로세스의 자원을 이용해서 실제로 작업을 수행하는 것이 바로 쓰레드이다.
그래서 모든 프로세스에는 최소한 하나 이상의 쓰레드가 존재하며, 둘 이상의 쓰레드를 가진 프로세스를 멀티쓰레드 프로세스라고 한다.
(쓰레드를 프로세스라는 작업공간(공장)에서 작업을 처리하는 일꾼으로 생각하자)
싱글쓰레드 프로세스 = 자원 + thread
멀티쓰레드 프로세스 = 자원 + thread + thread+..........
하나의 프로세스가 가질 수 있는 쓰레드의 개수는 제한되어 있지 않으나 쓰레드가 작업을 수행하는데 개별적인 메모리공간(호출 스택)을 필요로 하기 때문에 프로세스의 메모리 한계(호출 스택의 크기)
에 따라 생성할 수 있는 쓰레드의 수가 결정된다. 실제로는 프로세스의 메모리 한계에 다다를 정도로 많은 쓰레드를 생성하는 일은 없을 것이니 이에 관해서는 걱정하지 않아도 된다.
현재 우리가 사용하고 있는 윈도우나 유닉스를 포함한 대부분의 OS는 멀티태스킹(다중 작업)을 지원하기 때문에 여러 개의 프로세스가 동시에 실행될 수 있다.
멀티캐스팅과 마찬가지로 멀티쓰레딩은 하나의 프로세스 내에서 여러 쓰레드가 동시에 작업을 수행하는 것이 가능하다. 실제로는 한 개의 CPU가 한 번에 단 한가지 작업만 수행할 수 있기 때문에 아주 짧은 시간동안
여러 작업을 번갈아 가면 수행함으로써 동시에 여러 작업이 수행되는 것처럼 보이게 하는 것이다. 그래서 프로세스의 성능이 쓰레드의 개수에 비례하지 않으며, 하나의 쓰레드를 가진 프로세스 보다 두 개의 쓰레드를 가진 프로세스가 오히려 더 낮은 성능을 보일 수 있다.
도스와 같이 한번에 한가지 작업만 할 수 있는 OS와 윈도우와 같은 멀티태스킹이 가능한 OS의 차이는 이미 경험으로 잘 알 수 있을 것이다. 싱글쓰레드 프로그램과 멀티쓰레드 프로그램의 차이도 이와 같다고 생각하면 된다.
멀티쓰레딩의 장점
1 CPU의 사용률을 향상시킨다.
2 자원을 보다 효율적으로 사용할 수 있다.
3 사용자에 대한 응답성이 향상된다.
4 작업이 분리되어 코드가 간결해진다.
메신저의 경우 채팅하면서 파일을 다운로드 받거나 음성대화를 나눌 수 있는 것이 가능한 이유가 바로 멀티쓰레드로 작성되어 있기 때문이다. 만일 싱글쓰레드로 작성되어 있다면 파일을 다운로드 받는 동안에는 채팅을 할 수 없을 것이다. 여러 사용자에게 서비스를 해주는 서버 프로그램의 경우 멀티쓰레드로 작성하는 것은 필수적이어서 하나의 서버프로세스가 여러 개의 쓰레드를 생성해서 쓰레드와 사용자의 요청이 일대일로 처리되도록 멀티쓰레드로 프로그래밍해야 한다. 만일 싱글쓰레드로 서버프로그램을 작성한다면 사용자의 요청 마다 새로운 프로세스를 생성해야하는데 프로세스를 생성하는 것은 쓰레드를 생성하는 것에 비해 훨씬 더 많은 시간과 메모리공간을 필요하기 때문에 많은 수의 사용자 요청을 서비스하기 어렵다.
--> 쓰레드를 가벼운 프로세스 즉, 경량 프로세스하고 부르기도 한다.
그러나 멀티쓰레딩에 장점만 있는 것이 아니어서 멀티쓰레드 프로세스는 여러 쓰레드가 같은 프로세스 내에서 자원을 공유하면서 작업을 하기 때문에 발생할 수 있는 동기화, 교착상태(deadlock)와 같은 문제들을 고려해서 신중히 프로그래밍해야한다.
2. 쓰레드의 구현과 실행
쓰레드를 구현하는 방법은 Thread클래스를 상속받는 방법과 Runnable 인터페이스를 구현하는 방법, 모두 2가지가 있다.
그러나 Thread 클래스를 상속받으면 다른 클래스를 상속받을 수 없기 때문에, Runnable 인터페이스를 구현하는 방법이 일반적이다.
1) Thread 클래스를 상속
class MyThread extends thread{
public void run(){/*작업 내용*/}// Thread 클래스의 run()을 오버라이딩
}
2) Runnable 인터페이스를 구현
class MyThread implements Runnable{
public void run(){/*작업 내용*/}// Runnable인터페이스의 추상메서드 run()을 구현
}
Runnable 인터페이스는 run()메서드만 정의되어 간단한 인터페이스이다. Runnable 인터페이스를 구현하기 위해서 해야 할 일은 추상 메서드인 run()의 몸통을 만들어 주는 것일 뿐이다.
class ThreadEx1 {
public static void main(String args[]) {
A t1 = new A();
Runnable r = new B();
Thread t2 = new Thread(r); // 생성자 Thread(Runnable target)
// Runnable 인터페이스를 구현한 경우, Runnable 인터페이스를 구현한 클래스의 인스턴스를 생성한 다음, 이 인스턴스를 가지고 Thread 클래스의 인스턴스를 생성할 때 생성자의 매개변수로 제공해야 한다.
// 이 때 사용되는 Thread 클래스의 생성자는 Thread(Runnable target)로 호출시에 Runnable인터페이스를 구현한 클래스의 인스턴스를 넘겨줘야 한다.
t1.start();// 쓰레드를 생성한 다음에는 start()를 호출해야한 비로소 작업을 시작하게 된다.
t2.start();
//한 번 사용한 쓰레드는 다시 재사용할 수 없다. 즉 하나의 쓰레드에 대해 start()가 한 번만 호출될 수 있다는 뜻이다.
//그래서 쓰레드의 작업이 한 번 더 수행되기를 원한다면 오른쪽의 코드와 같이 새로운 쓰레드를 생성한 다음에 start()를 호출해야 한다.
}
}
class A extends Thread {
public void run() {
for(int i=0; i < 5; i++) {
System.out.println(getName()); // 조상인 Thread의 getName()을 호출, 즉 쓰레드의 이름을 반환한다.
}
}
}
class B implements Runnable {
public void run() {
for(int i=0; i < 5; i++) {
// Thread.currentThread() - 현재 실행중인 Thread를 반환한다.
System.out.println(Thread.currentThread().getName());
// Thread 클래스를 상속받으면, Thread 클래스의 메서드를 직접 호출할 수 있지만, Runnable을 구현하면 Thread클래스의 static 메서드인 currentThread()를 호출하여 쓰레드에 대한 참조를 얻어
// 와야만 호출이 가능하다.
}
}
}
실행결과)
Thread-0
Thread-0
Thread-0
Thread-0
Thread-0
Thread-1
Thread-1
Thread-1
Thread-1
Thread-1
(실행결과는 그때그때 달라요!~)
cf.) 인스턴스 변수로 Runnable타입의 변수 r을 선언해 놓고 생성자를 통해서 Runnable 인터페이스를 구현한 인스턴스를 참조하도록 되어 있는 것을 확인할 수 있다. 그리고 run()을 호출하면 참조변수 r을 통해서 Runnable 인터페이스를 구현한 인스턴스의 run()이 호출된다. 이렇게 함으로써 상속을 통해 run()을 오버라이딩하지 않고도 외부로부터 제공받을 수 있다.
3. start()와 run()
쓰레드를 실행시킬 때 run()이 아닌 start()를 호출한다는 것에 대해서 다소 의문을 들었을 것이다.
run()을 호출하는 것은 생성된 쓰레드를 실행시키는 것이 아니라 단순히 클래스에 속한 메서드 하나를 호출하는 것이다.
반면에 start()는 새로운 쓰레드가 작업을 실행하는데 필요한 호출스택을 생성한 다음에 run()을 호출해서, 생성된 호출스택에 run()이 첫 번째로 저장되게 한다.
모든 쓰레드는 독립적인 작업을 수행하기 위해 자신만의 호출스택을 필요로 하기 때문에, 새로운 쓰레드를 생성하고 실행시킬 때마다 새로운 호출스택이 생성되고 쓰레드가 종료되면 작업에 사용된 호출스택은 소멸된다.
(1) start()와 run() - 쓰레드의 호출 구조
main()에서 start()호출 -> start()에서 호출스택 생성 -> 호출스택에서 run()호출하여 쓰레드 작업수행 ->
호출스택이 2개이므로 스케쥴러가 정한 순서에 의해서 번갈아가며 작업 수행.
1 main 메서드에서 쓰레드의 start메서드를 호출한다.
2 start 메서드는 쓰레드가 작업을 수행하는데 사용될 새로운 호출스택을 생성한다.
3 생성된 호출스택에 run 메서드를 호출해서 쓰레드가 작업을 수행하도록 한다.
4 이제는 호출스택이 2개이기 때문에 스케줄러가 정한 순서에 의해 번갈아 가면서 실행된다.
호출스택에서는 가장 위에 있는 메서드가 현재 실행중인 메서드이고 나머지 메서드들은 대기상태에 있다.
그러나 쓰레드가 둘 이상일 때는 호출스택의 최상위에 있는 메서드 일지라도 대기상태에 있을 수 있다는 것을 알 수 있다.
스케줄러는 시작되었지만 아직 종료되지 않은 쓰레드들의 우선순위를 고려하여 실행 순서와 실행 시간을 결정하고 각 쓰레드들은 작성된 스케줄에 따라 자신의 순서가 되면 지정된 시간동안 작업을 수행한다.
cf.) start()가 호출된 쓰레드는 바로 실행되는 것이 아니라는 것에 주의하자. 일단 대기상태로 있다가 스케줄러가 정한 순서에 의해서 실행된다.
이때 주어진 시간동안 작업을 마치지 못한 쓰레드는 다시 자신의 차례가 돌아올 때 까지 대기상태에 있게 되며, 작업을 마친 쓰레드, 즉 run()의 수행이 종료된 쓰레드는 호출스택이 모두 비워지면서 이 쓰레드가 사용하던 호출스택은 사라진다.
자바프로그램을 실행하면 호출스택이 생성되고 main 메서드가 처음으로 호출되고 main 메서드가 종료되면 호출스택이 비워지고 프로그램이 종료되는 것과 정확히 일치한다.
쓰레드는 일꾼이다. 프로그램이 실행되기 위해서는 작업을 수행하는 일꾼이 최소한 하나는 필요하다. 그래서 프로그램을 실행하면 기본적으로 하나의 쓰레드(일꾼)를 생성하고, 그 쓰레드가 main 메서드를 호출해서 작업이 수행되도록 하는 것(main 메서드의 작업을 수행하는 것도 쓰레드이다.)이다.
지금까지는 main 메서드가 수행을 마치면 프로그램이 종료되었으나, main 메서드가 수행을 마쳤다하더라도 다른 쓰레드가 아직 작업을 마치지 않은 상태라면 프로그램이 종료되지 않는다.(실행중인 사용자 쓰레드가 하나도 없을 때 프로그램은 종료된다.)
class ThreadEx2 {
public static void main(String args[]) throws Exception {
MyThreadEx2_1 t1 = new MyThreadEx2_1();
t1.start();
}
}
class MyThreadEx2_1 extends Thread {
public void run() {
throwException();
}
public void throwException() {
try {
throw new Exception();
} catch(Exception e) {
e.printStackTrace();
}
}
}
실행결과)
java.lang.Exception
at MyThreadEx2_1.throwException(ThreadEx2.java:15)
at MyThreadEx2_1.run(ThreadEx2.java:10)
새로 생성한 쓰레드에서 고의로 예외를 발생시키고 printStackTrace()를 이용해서 예외가 발생한 당시의 호출스택을 출력하는 예제이다.
호출스택의 첫번째 메서드가 main 메서드가 아니라 run 메서드인 것을 확인하자.
그리고 한 스레드에서 예외가 발생해서 종료되어도 다른 쓰레드의 실행에는 영향을 미치지 않는다.
class ThreadEx3 {
public static void main(String args[]) throws Exception {
MyThreadEx3_1 t1 = new MyThreadEx3_1();
t1.run();
}
}
class MyThreadEx3_1 extends Thread {
public void run() {
throwException();
}
public void throwException() {
try {
throw new Exception();
} catch(Exception e) {
e.printStackTrace();
}
}
}
실행결과)
java.lang.Exception
at MyThreadEx3_1.throwException(ThreadEx3.java:15)
at MyThreadEx3_1.run(ThreadEx3.java:10)
at ThreadEx3.main(ThreadEx3.java:4)
이 예제 역시 고의적으로 예외를 발생시켜서 호출스택의 내용을 확인할 수 있도록 했다. 이전 예제와는 달리 main 메서드가 호출스택에 포함되어 있음을 확인하자.
4. 핵심
1 Thread를 상속받는 클래스는 독립적인 흐름을 갖는 하나의 쓰레드로서의 역할을 수행한다.
2 run()는 main() 쓰레드와 별개의 독립적인 실행 흐름을 갖는다. 또는 별개의 움직이는 실행 위치이다.
3 run()만하면 단순히 메소드 호출에 불과하다.--> 독립적인 실행을 하는 쓰레드가 아니다.
4 Runnable 인터페이스에는 start()라는 메서드가 없다. 그래서 Runnable을 매개변수로 갖는 Thread 생성자를 사용한다. 객체를 Thread 생성자의 매개변수로 담아 버리면 Thread 클래스와 같이 사용할 수 있다.
5 main () 쓰레드를 실행하면 main 메서드만 실행하는 클래스가 되나, 쓰레드이나, 만약 main() 하고 마치 동시에 실행되는 듯한 클래스를 만들고 싶다면 멀티쓰레드의 개념이 성립된다.
6 멀티쓰레드를 사용하면 여러개의 프로세스가 동시에 실행하는 듯한 모습을 보인다.
7 쓰레드라는 것은 프로세스이기 때문에 준비하는데 약간의 시간이 필요하다. t1.run()의 경우 단순히 메서드 호출하므로 시간이라는 것이 필요한것이 아니다.
 File 클래스
File 클래스