
Jsoup는 아주 강력하고 재미있는 라이브러리다. 단순한 HTML 문서 파싱을 넘어 웹 사이트에 대한 Request, Response를 모두 처리할 수 있다. 덕분에 일부 특별한 경우(플래시, 애플릿, ActiveX같은 비표준이나 WebSocket)가 아니라면 브라우저로 사이트를 이용하는 상황을 그대로 재현해낼 수 있다. 다시 말해, 대부분의 사이트의 원하는 정보만 뽑아내는 '뷰어'를 만들 수 있다는 것이다. 몇 가지 간단한 예제를 통해 사이트에서 원하는 정보만 뽑아내는 과정을 적어보려 한다.
0. Gradle 디펜전시 추가
compile group: 'org.jsoup', name: 'jsoup', version: '1.10.2'
Maven Repository를 통해 간단하게 디펜전시를 추가 할 수 있다.
Jsoup는 크게 static 메소드를 체이닝해서 URL(혹은 로컬HTML)에 연결하고 결과를 얻어오는 org.jsoup.Jsoup 패키지와 얻어온 결과의 구조를 위한 객체들이 포함된 org.jsoup.nodes 패키지, 연결 방법과 Response, Request등을 가지고 있는 org.jsoup.Connection 패키지로 이루어져 있다.
Jsoup의 주요 요소는 크게 다섯 가지로 볼 수 있다.
Document | Jsoup 얻어온 결과 HTML 전체 문서 |
Element | Document의 HTML 요소 |
Elements | Element가 모인 자료형. for나 while 등 반복문 사용이 가능하다. |
Connection | Jsoup의 connect 혹은 설정 메소드들을 이용해 만들어지는 객체, 연결을 하기 위한 정보를 담고 있다. |
Response | Jsoup가 URL에 접속해 얻어온 결과. Document와 다르게 status 코드, status 메시지나 charset같은 헤더 메시지와 쿠키등을 가지고 있다. |
Jsoup로 하는 작업은 크게 Connection 객체를 통해 URL에 접속하고(혹은 로컬 파일/문자열), Response 객체에서 세션ID같은 쿠키와 HTML Document를 얻어낸 후, Document의 Element들을 파싱하는 과정으로 나누어진다고 볼 수 있다.
1. URL 접속해 결과 얻어오기
URL에 접속해 Document를 얻어내기는 아주 쉽다.
// 간략화된 GET, POST
Document google1 = Jsoup.connect("http://www.google.com").get();
Document google2 = Jsoup.connect("http://www.google.com").post();
// Response로부터 Document 얻어오기
Connection.Response response = Jsoup.connect("http://www.google.com")
.method(Connection.Method.GET)
.execute();
Document google3 = response.parse();
http://www.google.com에 접속하는 방법들
얻어낸 Document는 두가지 방법으로 출력할 수 있다. .html() 메소드와 .text() 메소드 두 가지다.
Connection.Response response = Jsoup.connect("http://www.google.com")
.method(Connection.Method.GET)
.execute();
Document document = response.parse();
String html = document.html();
String text = document.text();
html과 text는 JQuery의 메소드와 유사하다. 문서의 html 그 자체를 가져올지, html 태그 사이의 문자열만을 가져올지를 택하는 것이다.
document.html()의 결과
<!doctype html> <html itemscope itemtype="http://schema.org/WebPage" lang="ko"> <head> <meta content="/images/branding/googleg/1x/googleg_standard_color_128dp.png" itemprop="image"> <link href="/images/branding/product/ico/googleg_lodp.ico" rel="shortcut icon"> <meta content="origin" id="mref" name="referrer"> <title>Google</title> <script>(function(){window.google={kEI:'P7QKWeJtioTzBfTmg6AB',kEXPI:'1352553,3700294,3700347,4029815,4031109,4032677,4036527,4038214,4038394,4039268,4041776,4043492,4045096,4045293,4045841,4046904,4047140,4047454,4048347,4048980,4050750,4051887,4056126,4056682,4058016,4061666,4061980,4062724,4064468,4064796,4065786,4069829,4071757,4071842,4072270,4072364,4072774,4076095,4076999,4078430,4078588,4078763,4080760,4081038,4081165,4082131,4082230,4083046,4090550,4090553,4090806,4091353,4092934,4093313,4093498,4093524,4094251,4094544,4094837,4095910,4095999,4096323,4097150,4097922,4097929,4098096,4098458,4098721,4098728,4098752,4100169,4100174,4100376,4100679,4100714,4100828,4101376,4101429,4101750,4102028,4102032,4102107,4102238,4103215,4103254,4103475,4103845,4103849,4103999,4104202,4104204,4104527,4105085,4105099,4105178,4105317,4105470,4105788,4106085,4106209,4106949,4107094,4107221,4107395,4107422,4107525,4107555,4107628,4107634,4107807,4107895,4107900,4107957,4107966,4107968,4108012,4108016,4108027,4108033,4108417,4108479,4108537,4108539,4108553,4108687,4108885,4109075,4109293,4109316,4109489,4109498,4110094,8300508,8503585,8508113,8508229,8508931,8509037,8509373,8509826,10200083,10200096,19001874,19002112,19002127,41027342',authuser:0,j:{en:1,bv:24,pm:'p',u:'c9c918f0',qbp:0},kscs:'c9c918f0_24'};google.kHL='ko';})();(function(){google.lc=[];google.li=0;google.getEI=function(a){for(var b;a&&(!a.getAttribute||!(b=a.getAttribute("eid")));)a=a.parentNode;return b||google.kEI};google.getLEI=function(a){for(var b=null;a&&(!a.getAttribute||!(b=a.getAttribute("leid")));)a=a.parentNode;return b};google.https=function(){return"https:"==window.location.protocol};google.ml=function(){return null};google.wl=function(a,b){try{google.ml(Error(a),!1,b)}catch(c){}};google.time=function(){return(new Date).getTime()};google.log=function(a,b,c,d,g){a=google.logUrl(a,b,c,d,g);if(""!=a){b=new Image;var e=google.lc,f=google.li;e[f]=b;b.onerror=b.onload=b.onabort=function(){delete e[f]};window.google&&window.google.vel&&window.google.vel.lu&&window.google.vel.lu(a);b.src=a;google.li=f+1}};google.logUrl=function(a,b,c,d,g){var e="",f=google.ls||"";c||-1!=b.search("&ei=")||(e="&ei="+google.getEI(d),-1==b.search("&lei=")&&(d=google.getLEI(d))&&(e+="&lei="+d));a=c||"/"+(g||"gen_204")+"?atyp=i&ct="+a+"&cad="+b+e+f+"&zx="+google.time();/^http:/i.test(a)&&google.https()&&(google.ml(Error("a"),!1,{src:a,glmm:1}),a="");return a};google.y={};google.x=function(a,b){google.y[a.id]=[a,b];return!1};google.lq=[];google.load=function(a,b,c){google.lq.push([[a],b,c])};google.loadAll=function(a,b){google.lq.push([a,b])};}).call(this); google.j.b=(!!location.hash&&!!location.hash.match('[#&]((q|fp)=|tbs=rimg|tbs=simg|tbs=sbi)')) ||(google.j.qbp==1);(function(){google.hs={h:true,pa:true,q:false};})();(function(){goo (이하 생략) |
document.text()의 결과
Google 스크린 리더 사용자는 여기를 클릭하여 Google 순간 검색을 설정 해제하시기 바랍니다. Gmail 이미지 로그인 Google 순간 검색을 사용할 수 없습니다. 검색어를 입력한 후 Enter를 누르세요. 자세히 알아보기 Google연결 속도 문제로 순간 검색이 중지되었습니다. 검색하려면 Enter를 누르세요. 검색하려면 Enter를 누르세요. 부적절한 예상 검색어 신고 × 한국 'Ok Google'이라고 말하면 음성 검색이 시작됩니다. 손가락 하나 움직이지 않고 검색해 보세요. 'Ok Google' 다음에 말한 내용을 Chrome에서 검색합니다. 자세히 알아보기아니요'Ok Google' 사용 개인정보처리방침 약관 설정 검색 설정 고급검색 기록 검색 도움말 의견 보내기 Google.com 사용 광고 비즈니스 Google 정보 내 계정 검색 지도 YouTube Play 뉴스 Gmail 드라이브 캘린더 Google+ 번역 사진더보기 문서 도서 Blogger 주소록 행아웃 KeepGoogle 제품 모두 보기 |
이 두가지 메소드는 Document뿐 아니라 Element에도 구현되어 있다.
2. 얻어온 결과에서 특정 값 뽑아내기
특정 값, 그러니까 특정한 html 요소를 얻으려면 select("css query") 메소드를 사용하면 된다.
구글 메인 페이지 검색 버튼의 value를 얻어 보자.
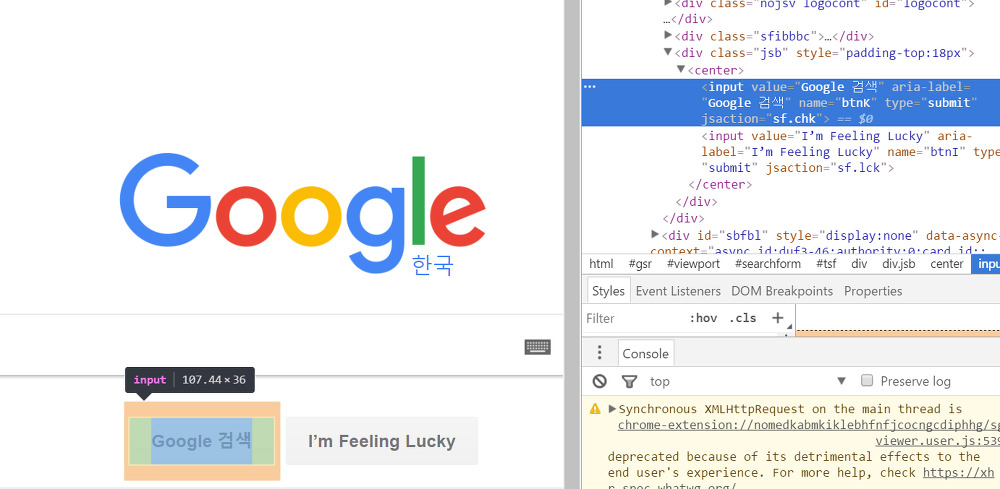
검색 버튼의 name은 btnK다.
Connection.Response response = Jsoup.connect("http://www.google.com")
.method(Connection.Method.GET)
.execute();
Document googleDocument = response.parse();
Element btnK = googleDocument.select("input[name=btnK]").first();
String btnKValue = btnK.attr("value");
System.out.println(btnKValue); // Google 검색
select의 결과는 Elements다. 그 중 첫번째 Element를 first() 메소드로 선택했다.
※ 목표가 있는 예제
불법만화로 유명한 그 사이트(머루)의 뷰어를 만든다고 상상해보자.
얻어내야 할 값은 크게 두 가지다.
1. 만화의 목록
2. 만화의 이미지 파일
이 값들을 얻어내기 위해서는
1) 만화 목록을 얻어낸다. 2) 글 내용에서 실제 만화 이미지가 있는 링크를 얻어낸다. 3) 이미지가 있는 링크에 접속한 후 이미지를 뽑아낸다. |
이렇게 세 가지 과정으로 진행해 보자.
1) 만화 목록 얻어내기
앞서 살펴본 Jsoup의 Conenction 메소드를 이용해 '업데이트' 페이지에 접속해 Doucment를 얻어낸다.
Document rawData = Jsoup.connect(URL)
.timeout(5000)
.get();
이 불법적이고 무서운 사이트는 Request Header를 검사하지 않는다. 그래서 위 코드처럼 아무런 추가적인 정보 없이 간단하게 결과를 얻어 올 수 있다. 하지만 Request를 철저하게 검사하는 사이트에는 더 많은 정보가 필요하다. 그런 사이트는 다음 글에 적을 예정이다.
아무튼, 이제 얻어낸 Document에서 정보를 뽑아낼 차례다. 구글 크롬의 개발자 도구를 이용해 업데이트 페이지를 확인해 보자.
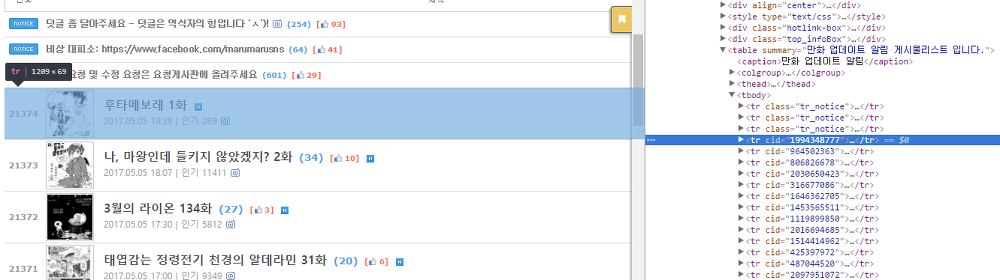
'업데이트' 페이지 HTML
게시판은 table 태그를 사용하고, 각 행은 tr 태그에 매칭되며 공지사항은 tr_notice 클래스를 가지고 있다는 사실을 알 수 있다.
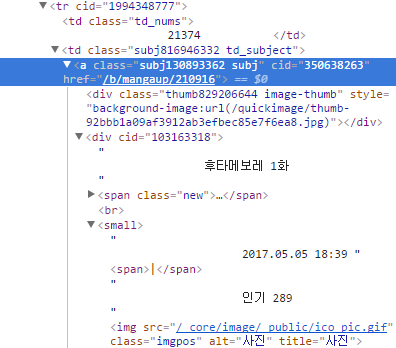
tr 태그의 내부
tr 태그에 포함된 요소들을 살펴보자.
a 태그로 글 내용에 해당하는 url을 얻을 수 있고, a태그의 첫번째 div에서 제목을 얻을 수 있다. 마지막으로 small 태그를 통해 글이 작성된 날짜를 얻을 수 있다.
이렇게 얻어낸 사실들을 직접 코드로 구현하자.
Elements articles = rawData.select("tr:not(.tr_notice) a"); // 공지사항을 제외한 tr의 a 태그들을 얻어온다.
for(Element article : articles) {
String href = article.attr("abs:href"); // a태그 href의 절대주소를 얻어낸다.
// a 태그 안에 포함된 div들
Elements articleDiv = article.select("div");
String thumbUrl = ROOT_URL
+ articleDiv.first() // 첫 번째 div에서 썸네일 url을 얻어온다.
.attr("style")
.replace("background-image:url(", "")
.replace(")", "");
String title = articleDiv.get(1).ownText(); // 두 번째 div에서 제목을 얻어낸다.
String date = articleDiv.get(1).select("small").text()
.split("\\|")[0];
System.out.println(href); // http://ma../b/mangup/00000
System.out.println(thumbUrl); // http://ma../quickimage/...
System.out.println(title); // 제목
System.out.println(date); // 날짜
}
얻어내고자 한 요소들을 css 선택지로 얻어낸 후, split이나 replace등의 메소드를 이용해 정리한다.
이 '글 목록'에 해당하는 정보는 필요에 맞게 정의한 객체에 담아 보관하거나 유저에게 보여 줄 수 있다.
2) 글 내용에서 만화가 있는 링크 얻어내기
위에서 얻어낸 글 내용 url에 접속한 후, 실제 이미지가 있는 페이지에 접근할 차례다. 태그 분석을 위해 브라우저로 페이지에 직접 들어가 보자.
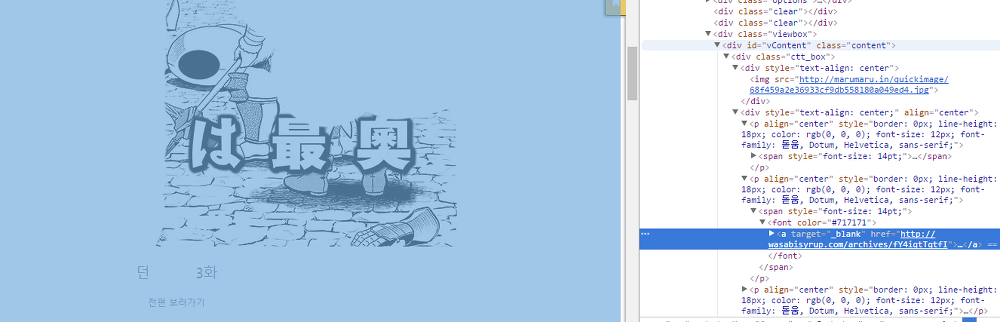
글 내용 HTML
글의 내용에 해당하는 div(#vContent)의 첫 번째 a 태그의 href 속성이 실제 만화 이미지가 포함된 URL이다.
Document rawData = Jsoup.connect(ARTICLE_URL)
.timeout(5000)
.get();
Elements contentATags = rawData.select("#vContent a"); // 공지사항을 제외한 tr의 a 태그들을 얻어온다.
String viewPageUrl = contentATags.first()
.attr("abs:href"); // 마찬가지로 절대주소 href를 얻어낸다
System.out.println(viewPageUrl); // http://wasabi.../archives/XXXXX...
아주 간단하게 이미지들이 포함된 주소를 얻어낼 수 있다.
3) 만화 이미지가 있는 URL에 접속해 이미지 URL 얻어내기
마찬가지로 만화 이미지가 포함된 URL에 접속해 태그를 분석한다.
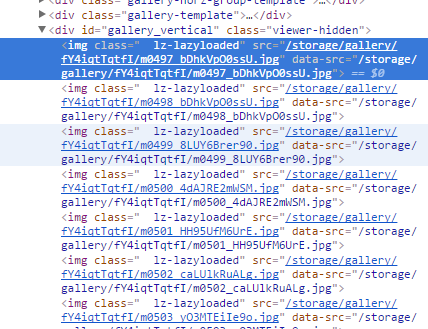
만화 이미지가 있는 페이지의 HTML
html 코드를 보면 이미지들이 가진 특정 클래스가 있다. 이 클래스를 가진 img 태그들을 얻어낸 후, data-src 속성을 뽑아내자.
Document rawData = Jsoup.connect(VIEWER_URL)
.timeout(5000)
.get();
Elements imgs = rawData.select("img[class=lz-lazyload]"); // lz-lazyload 클래스를 가진 img들
List<String> imageUrls = new ArrayList<>();
for(Element img : imgs) {
imageUrls.add(img.attr("abs:data-src"));
}
System.out.println(imageUrls); // 이미지 URL들.
}
만화 내용이 되는 모든 이미지 URL을 뽑아넀다. 이 URL에 접속해 직접 파일로 다운로드 할 수도, 자기 나름의 뷰어에 출력 할 수도 있다. 또, 목록을 얻어 낼 때 필요한 data들을 포함함으로써 원하는 페이지나 검색까지 구현이 가능하다.
 [펌]자바 Crawling(크로울링) 로그인 해 긁어오기
[펌]자바 Crawling(크로울링) 로그인 해 긁어오기