우선 형태소 분석기를 다운로드 하신 다음에
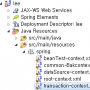
이클립스에서 프로젝트 추가 하신후
KoreanFilterFactory, KoreanTokenizerFactory 이 두개의 클래스를 추가 하시면 됩니다.
추가를 하시면 BaseTokenFilterFactory, BaseTokenizerFactory 이 두개의 클래스가 없기 때문에 오류가 발생을 한 것인데 solr lib를 require project로 잡으셔도 되고 lib를 받아서 빌드패스에 잡으시고 빌드를 하시면 됩니다.
package org.apache.lucene.analysis.kr;
import org.apache.lucene.analysis.TokenStream;
import org.apache.solr.analysis.BaseTokenFilterFactory;
public class KoreanFilterFactory extends BaseTokenFilterFactory {
public KoreanFilter create(TokenStream input) {
return new KoreanFilter(input);
}
}
package org.apache.lucene.analysis.kr;
import java.io.Reader;
import org.apache.solr.analysis.BaseTokenizerFactory;
public class KoreanTokenizerFactory extends BaseTokenizerFactory {
public KoreanTokenizer create(Reader input) {
return new KoreanTokenizer(input);
}
}
빌드 후 koreananalizer.jar로 저장 한 후. was의 lib 경로에 넣습니다.
example로 들어있는 jetty에서는 lib를 어디에 넣어야 할지를 몰라서
한참을 해메다가 work/WEB-INF/lib에 넣었더니 동작을 하더군요
schema.xml에 text필드를 아래와 같이 수정합니다.
<fieldType name="text" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<!--<tokenizer class="solr.WhitespaceTokenizerFactory"/>-->
<tokenizer class="org.apache.lucene.analysis.kr.KoreanTokenizerFactory"/>
<filter class="org.apache.lucene.analysis.kr.KoreanFilterFactory"/>
<filter class="solr.StopFilterFactory"
ignoreCase="true"
words="stopwords.txt"
enablePositionIncrements="true"
/>
<filter class="solr.WordDelimiterFilterFactory" generateWordParts="1" generateNumberParts="1" catenateWords="1" catenateNumbers="1" catenateAll="0" splitOnCaseChange="1"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.EnglishPorterFilterFactory" protected="protwords.txt"/>
<filter class="solr.RemoveDuplicatesTokenFilterFactory"/>
</analyzer>
<analyzer type="query">
<!-- <tokenizer class="solr.WhitespaceTokenizerFactory"/>-->
<tokenizer class="org.apache.lucene.analysis.kr.KoreanTokenizerFactory"/>
<filter class="org.apache.lucene.analysis.kr.KoreanFilterFactory"/>
<filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt"/>
<filter class="solr.WordDelimiterFilterFactory" generateWordParts="1" generateNumberParts="1" catenateWords="0" catenateNumbers="0" catenateAll="0" splitOnCaseChange="1"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.EnglishPorterFilterFactory" protected="protwords.txt"/>
<filter class="solr.RemoveDuplicatesTokenFilterFactory"/>
</analyzer>
</fieldType>
기존의 solr.WhitespaceTokenizerFactory를 주석 처리 하고 새로 생성한 KoreanTokenizerFactory를 tokenizer class로 넣었습니다.
제가 환경이 되면 검색하는 모습도 보여드리고 싶은데 환경이 안되는군요
ps. 한글 검색 시에는 http://localhost:8983/solr/admin/ 에서 검색 하셔야 합니다. tutorial에서 나오는 것 같이 url에 q값에 한글을 넣으면 오류를 발생합니다