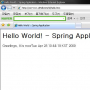
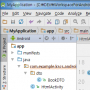
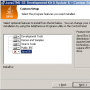
한글 문제는 항상 사람 발목을 잡는다. OTL.
Nutch 0.9를 이용해서
1) 자동적으로 Incremental Crawling을 하고,
2) 한글에 대해서 검색이 가능하고,
3) 웹 인터페이스가 가능하게 해 보자.
1. Nutch 0.9 소스를 다운받는다.
svn co http://svn.apache.org/repos/asf/lucene/nutch/tags/release-0.9/ ./nutch
export NUTCH_HOME ./nutch
2. Nutch 0.9 이하는 (0.8도 포함) 버그를 가지고 있어서 한글를 문자로 인식하지 않는다. 한글을 문자로 인식시키려면 NutchAnalysis.jj를 수정해야 한다.
2-1) NuchAnalysis.jj에 한글 영역을 추가 한다.
vi $NUTCH_HOME/src/java/org/apache/nutch/analysis/NuchAnalysis.jj
164라인부터 시작되는 CJK 부분을
변경전 :
| <#CJK: // non-alphabets
[
"\u3040"-"\u318f",
"\u3300"-"\u337f",
"\u3400"-"\u3d2d",
"\u4e00"-"\u9fff",
"\uf900"-"\ufaff"
]
>
변경후:
| <#CJK: // non-alphabets
[
"\u3040"-"\u318f",
"\u3300"-"\u337f",
"\u3400"-"\u3d2d",
"\u4e00"-"\u9fff",
"\uac00"-"\ud7a3",
"\uf900"-"\ufaff"
]
>
로 바꾸어 준다. "\uac00"-"\ud7a3"는 UTF-8에서 한글이 차지하는 영역이다.
2-1) NuchAnalysis.jj를 빌드하여 .java파일을 만든다.
cd src/java/org/apache/nutch/analysis
javacc NutchAnalysis.jj
3. Nutch 전체를 빌드 한다.
cd $NUTCH_HOME
ant
4. 웹을 크롤링 한다. 우선, JAVA_HOME 과 CATALINA_HOME이 설정되어 있어야 한다. 크롤링은 다음을 참조한다.
http://lucene.apache.org/nutch/tutorial8.html#Whole-web+Crawling
4-옵션) 자동적으로 클롤링을 하기 위해 Nutch 홈페이지에 있는 스크립트를 사용한다.
http://wiki.apache.org/nutch/Crawl
이 문서에 있는 스크립트에 일부 버그가 있어서, 수정 할 부분이 있다.
* 라인1
수정 전 :
#!/bin/sh
수정 후 :
#!/bin/bash
* 라인 38
수정 전 :
echo runbot: $0 could not find environment variable NUTCH_HOME
수정 후 :
echo runbot: $0 could not find environment variable CATALINA_HOME
그리고 cron을 이용해서 실행하려면, 위에서 JAVA_HOME 을 설정 해 주고 스크립트 중간에 cd $NUTCH_HOME을 해 주는 것이 낫다.
위의 파일을 $NUTCH_HOME/bin/runbot 으로 저장한다.
5. WAR파일을 빌드 한다.
cd $NUTCH_HOME
ant war
6. Tomcat에서 URL전송을 UTF-8을 이용하도록 설정한다.
vi $CATALINA_HOME/conf/server.xml
수정 전 :
<Connector port="8080" maxHttpHeaderSize="8192"
maxThreads="150" minSpareThreads="25" maxSpareThreads="75"
enableLookups="false" redirectPort="8443" acceptCount="100"
connectionTimeout="20000" disableUploadTimeout="true" />
수정 후 :
<Connector port="8080" maxHttpHeaderSize="8192"
maxThreads="150" minSpareThreads="25" maxSpareThreads="75"
enableLookups="false" redirectPort="8443" acceptCount="100"
connectionTimeout="20000" disableUploadTimeout="true"
URIEncoding="UTF-8" />
7. Tomcat Manager를 이용해서 $NUTCH_HOME/build/nutch-0.9.war 를 Deploy한다. 주의할 점은 $NUTCH_HOME/nutch-0.9.war 와 헷갈리지 않도록 한다.
Tomcat Manager에서 Deploy하는 방법은
http://peterpuwang.googlepages.com/NutchGuideForDummies.htm
에서 5. Web Searching based on the crawling result above: 이하를 따라한다.
$CATALINA_HOME/webapps/nutch-0.9/WEB-INF/classes/nutch-site.xml 파일의 설정은 반드시 필요하다.
<configuration>
<property>
<name>searcher.dir</name>
<value>크롤링된 문서가 있는 폴더 ($NUTCH_HOME/crawl 의 절대경로)</value>
</property>
</configuration>
이 문서의 핵심:
1) NutchAnalysis.jj 에 한글 범위를 추가하고 새로 빌드.
2) $CATALINA_HOME/conf/server.xml 에서 URL을 UTF-8으로 처리하도록 설정.
주 :
NutchAnalysis.jj를 보면,
( token=<WORD> | token=<ACRONYM> | token=<SIGRAM>)
| <SIGRAM: <CJK> >
이기 때문에, 한글은 각각의 글자가 하나의 토큰으로 처리가 된다.
"검색을 잘 하고 싶다" 로 쿼리를 넣으면, 분석후 나온 결과는 "검 색 을 잘 하 고 싶 다" 가 된다.
이런 경우 결과가 만족스럽지 못한 경우가 생기는데
<SIGRAM: (<CJK>)+ >
로 수정하면 단어 전체가 하나의 토큰이 된다.
이러한 경우에는 "검색을" 이란 쿼리는 "검색은" 을 포함하는 문서를 검색 하지 못한다.
내 생각에는 <SIGRAM: (<CJK>)+ > 으로 하거나 Korean이라는 별도의 텀을 만들어서, 형태소 분석을 수행해야 겠다.
고려대 형태소 분석기가 있지만 C버전을 가지고 있기 때문에 힘들고 Porter Stemmer처럼 무식한(?) 어미 처리기를 만들어 봐야 겠다.
 [패스트캣]1. 시작하기 - 설치
[패스트캣]1. 시작하기 - 설치
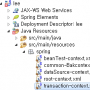 자바 스프링, spring AOP 구현 (xml 방식)
자바 스프링, spring AOP 구현 (xml 방식)