
먼저 루씬은 참 쓰기 편하면서도 커스터마이징하기는 참 불편한 특징을 갖고 있습니다. (물론 제 수준상으로...)
그래서 루씬을 이용해서 쓰기 편하게(?) 나름대로 만들어봤습니다.
지금부터 루씬을 이용해서 기본적인 검색기를 뚝딱 만들어보겠습니다.
먼저 색인할 데이터를 다운 받습니다.
[트윗 데이터]
 data.zip
data.zip위 파일은 JSON 형태의 트윗을 모아둔 파일로 압축을 풀면 약 45M 정도가 됩니다.
먼저 이 데이터를 원하시는 경로에 풀어둡니다.
저는 D:/tweet/ 에 압축을 풀겠습니다.
트윗을 담기 위한 객체를 만들어 둡니다.
객체 이름은 당연히 Tweet으로 하고 소스 내용은 아래와 같습니다.
package kr.peopleware.lucene.model;
import java.util.List;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.NumericField;
public class Tweet extends BaseModel{
private long tweetId;
private String contents;
private long createdAt;
private long crawledAt;
private boolean linked;
private List<String> urls;
public long getTweetId() {
return tweetId;
}
public void setTweetId(long tweetId) {
this.tweetId = tweetId;
}
public String getContents() {
return contents;
}
public void setContents(String contents) {
this.contents = contents;
}
public long getCreatedAt() {
return createdAt;
}
public void setCreatedAt(long createdAt) {
this.createdAt = createdAt;
}
public long getCrawledAt() {
return crawledAt;
}
public void setCrawledAt(long crawledAt) {
this.crawledAt = crawledAt;
}
public boolean isLinked() {
return linked;
}
public void setLinked(boolean linked) {
this.linked = linked;
}
public List<String> getUrls() {
return urls;
}
public void setUrls(List<String> urls) {
this.urls = urls;
}
@Override
public Document convetDocument() {
Document doc = new Document();
NumericField createdAt = new NumericField("createdAt",Field.Store.YES,true);
createdAt.setLongValue(this.getCreatedAt());
doc.add(createdAt);
NumericField tweetId = new NumericField("tweetId",Field.Store.YES,false);
tweetId.setLongValue(this.getTweetId());
doc.add(tweetId);
String type = "all";
if(this.getUrls() == null || this.getUrls().size() == 0){
type="link";
}
doc.add(new Field("type",type,Field.Store.NO,Field.Index.NOT_ANALYZED));
if(this.getUrls() != null){
doc.add(new Field("urls",this.getUrls().toString(),Field.Store.YES,Field.Index.NOT_ANALYZED));
}
doc.add(new Field("contents", this.getContents(), Field.Store.YES, Field.Index.ANALYZED));
return doc;
}
}
이때 BaseModel을 익스텐드 시켜서 사용했는데 BaseModel은 아래와 같습니다.
package kr.peopleware.lucene.model;
import org.apache.lucene.document.Document;
public abstract class BaseModel {
public abstract Document convetDocument();
}
BaseModel은 Tweet이란 객체를 루씬 색인에 사용할 수 있게끔 Document로 변환시켜주는 역할을 합니다.
그럼 이제 데이터를 담아둘 객체는 생성이 끝났습니다.
이제 데이터를 가져오는 부분을 만들어 보겠습니다.
간단히 만들기 위해서 main 클래스 내에 getTweets라는 메소드를 만들겠습니다.
이 메소드는 주어진 경로에 따라서 데이터를 List 형태로 반환하는 역할을 합니다.
private static List<Tweet> getTweets(String path) {
List<Tweet> tweetList = new ArrayList<Tweet>();
List<String> filenames = FileUtil.getFileNames(path);
for (String filename : filenames) {
List<String> lines = null;
try {
lines = FileUtil.load2List(filename);
} catch (Exception e) {
e.printStackTrace();
}
if(lines == null){
continue;
}
for (String line : lines) {
Tweet t = convertTweet((DBObject) JSON.parse(line));
tweetList.add(t);
}
// System.out.println(filename);
}
return tweetList;
}
여기서 주어진 path로부터 데이터를 한줄 한줄 가져오게 됩니다. 이 때 각 한줄 한줄을 Tweet이라는 객체로 변환 시켜야합니다. 그래서 convertTweet이라는 메소드를 생성하여 변환시켜줍니다. JSON 형태를 Tweet이라는 객체로 변환시켜주는 역할을 합니다. 그리고 JSON.parse는 몽고디비 라이브러리에서 제공하는 유틸리티입니다.
convertTweet역시 귀찮기 때문에 main 클래스 내에 만들겠습니다.
private static Tweet convertTweet(DBObject obj) {
Tweet tweet = new Tweet();
tweet.setTweetId((Long) obj.get("tweetId"));
tweet.setContents((String) obj.get("contents"));
tweet.setCreatedAt((Long) obj.get("createdAt"));
tweet.setCrawledAt((Long) obj.get("crawledAt"));
tweet.setLinked((Boolean)obj.get("linked"));
@SuppressWarnings("unchecked")
List<String> urls = (List<String>) obj.get("urls");
if(urls != null){
tweet.setUrls(urls);
}
return tweet;
}
그럼 여기까지 데이터를 가져와서 객체에 담는것 까진 완성이 되었습니다.
그럼 이제 실제 색인을 해보도록 하겠습니다.
이 글에서는 루씬을 해부하는 것이 아니라 루씬을 이용한 검색기를 만드는 것이 중요하기 때문에 루씬 자체에 대한 사용방법은 이 글에서는 생략하겠습니다.
먼저 위에 getTweets와 convertTweet이 포함된 메인 클래스 입니다.
package kr.peopleware.lucene.index.test;
import java.util.ArrayList;
import java.util.List;
import kr.peopleware.lucene.index.Indexer;
import kr.peopleware.lucene.index.properties.PropertiesManager;
import kr.peopleware.lucene.model.Tweet;
import kr.peopleware.util.file.FileUtil;
import org.apache.lucene.analysis.cjk.CJKAnalyzer;
import org.apache.lucene.util.Version;
import com.mongodb.DBObject;
import com.mongodb.util.JSON;
public class IndexTester {
/**
* @param args
*/
public static void main(String[] args) {
// TODO Auto-generated method stub
PropertiesManager pm = new PropertiesManager("index.properties");
Indexer indexer = new Indexer(new CJKAnalyzer(Version.LUCENE_36),"index.properties");
List<Tweet> tweetList = getTweets(pm.getProperty("TARGET_PATH"));
for (Tweet tweet : tweetList ) {
indexer.index(tweet);
}
indexer.commit();
indexer.close();
}
private static List<Tweet> getTweets(String path) {
List<Tweet> tweetList = new ArrayList<Tweet>();
List<String> filenames = FileUtil.getFileNames(path);
for (String filename : filenames) {
List<String> lines = null;
try {
lines = FileUtil.load2List(filename);
} catch (Exception e) {
e.printStackTrace();
}
if(lines == null){
continue;
}
for (String line : lines) {
Tweet t = convertTweet((DBObject) JSON.parse(line));
tweetList.add(t);
}
// System.out.println(filename);
}
return tweetList;
}
private static Tweet convertTweet(DBObject obj) {
Tweet tweet = new Tweet();
tweet.setTweetId((Long) obj.get("tweetId"));
tweet.setContents((String) obj.get("contents"));
tweet.setCreatedAt((Long) obj.get("createdAt"));
tweet.setCrawledAt((Long) obj.get("crawledAt"));
tweet.setLinked((Boolean)obj.get("linked"));
@SuppressWarnings("unchecked")
List<String> urls = (List<String>) obj.get("urls");
if(urls != null){
tweet.setUrls(urls);
}
return tweet;
}
}
메인클래스에서 보면 "index.properties"라는 인자를 사용하게 됩니다.
이는 properties에서 색인 할 데이터의 경로, 색인이 저장될 경로등을 설정하기 위한 것입니다.
index.properties 파일 내용을 살펴보면
SHUTDOWN = false TARGET_PATH = D://tweet INDEX_PATH = D://tweetIndex #open mode (create,append,create_or_append) OPEN_MODE = create #merge setting MERGE_POLICY = true MAX_MERGE_AT_ONCE = 100 SEGMENTS_PER_TIER = 100
아래 merge setting은 루씬과 직접적인 관계가 있는 설정입니다만, 기본적인 검색기를 만드는데는 그냥 저 값을 사용해도 무방합니다.
SHUTDOWN은 추후에 실시간 색인을 위한 옵션으로 현재는 사용하지 않습니다.
TARGET_PATH는 아까 data.zip의 압축을 푼 경로를 적습니다.
INDEX_PATH는 색인 데이터가 저장될 공간으로 원하는 곳에 경로를 적어주시면 됩니다.
OPEN_MODE는 색인기를 실행시에 기존 데이터를 새로 덮어쓸지(create), 기존 데이터에 추가 할 지(append)의 여부를 나타냅니다.
위 설정 파일의 설정을 마치면 이제 실행만 시키면 색인이 완료됩니다.
======================= 색인 끝 ======================
색인이 완료된 후 색인된 데이터를 검색해보도록 하겠습니다.
검색은 매우 심플합니다.
package kr.peopleware.lucene.search.test;
import java.util.Date;
import kr.peopleware.lucene.search.Searcher;
import kr.peopleware.lucene.util.QueryBuilder;
import org.apache.lucene.analysis.cjk.CJKAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.util.Version;
public class SearchTester {
/**
* @param args
*/
public static void main(String[] args) {
//설정 파일을 세팅하여 Searcher 생성
Searcher search = new Searcher("search.properties");
// search.setSort("tweetId",SortField.LONG,true);
//색인된 데이터의 contents에 "감기"라는 검색어를 넣어서 검색
Document[] docs = search.getDocuments(QueryBuilder.makeQuery("contents", "감기",new CJKAnalyzer(Version.LUCENE_36)));
int count = 0;
for (Document document : docs) {
if(count == 10)break;
System.out.println("["+count+"]");
System.out.println(document.get("urls"));
System.out.println(document.get("tweetId"));
Date date = new Date(Long.parseLong(document.get("createdAt")));
System.out.println(date);
System.out.println(document.get("contents"));
System.out.println();
count++;
}
System.out.println(docs.length);
search.close();
}
}
역시 search.properties란 파일을 사용하는데 search.properties에는 아래와 같이 색인 파일의 경로만이 저장되어있습니다.
INDEX_PATH = D://tweetIndex
또한 QueryBuilder라는 static 메소드가 있는데 이는 질의어를 만들어주기 위한 메소드입니다.
소스 내용은 아래와 같습니다만, 굳이 보실 필요는 없을 것 같습니다.
package kr.peopleware.lucene.util;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.index.Term;
import org.apache.lucene.search.BooleanClause;
import org.apache.lucene.search.BooleanQuery;
import org.apache.lucene.search.NumericRangeQuery;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.QueryTermVector;
import org.apache.lucene.search.TermQuery;
public class QueryBuilder {
public static Query makeQuery(String field,String q,Analyzer analyzer)
{
BooleanQuery bq = new BooleanQuery();
QueryTermVector qtv = new QueryTermVector(q, analyzer);
for(int i=0;i<qtv.size();i++)
{
bq.add(new TermQuery(new Term(field,qtv.getTerms()[i])), BooleanClause.Occur.MUST);
}
return bq;
}
public static Query makeQuery(String field, Object a,Object b){
Query nq = null;
if(a.getClass() == Integer.class){
nq = NumericRangeQuery.newIntRange(field, (Integer)a, (Integer)b, true, true);
}else if(a.getClass() == Double.class){
nq = NumericRangeQuery.newDoubleRange(field, (Double)a, (Double)b, true, true);
}else if(a.getClass() == Float.class){
nq = NumericRangeQuery.newFloatRange(field, (Float)a, (Float)b, true, true);
}else if(a.getClass() == Long.class){
nq = NumericRangeQuery.newLongRange(field, (Long)a, (Long)b, true, true);
}
return nq;
}
}
이제 검색을 해보면 아래와 같은 결과를 보실 수 있습니다.
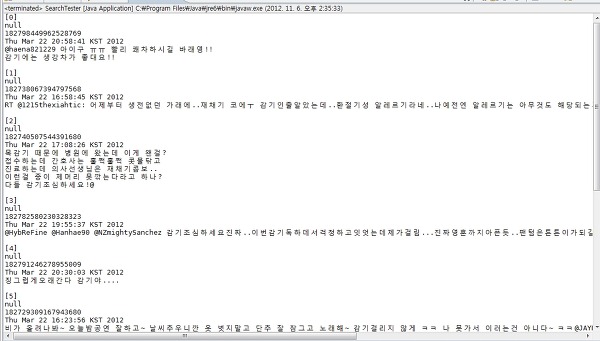
이클립스 프로젝트 파일도 함께 올려두겠습니다.
[루씬 프로젝트 파일]
[루씬 프로젝트를 사용하는데 필요한 라이브러리]
기본적인 검색 엔진은 이제 만들 수 있습니다만,
한글 검색 엔진은 "색인어 추출기"가 핵심이라고 말씀드릴 수 있습니다.
시간이 나는대로 형태소 분석기를 마무리 지어서 공개하도록 하겠습니다.
 쿠키와 세션을 이용한 자동 로그인 처리
쿠키와 세션을 이용한 자동 로그인 처리
 자바 스프링프레임워크 개발환경 설정하기-1편
자바 스프링프레임워크 개발환경 설정하기-1편