
샤딩의 한계
카카오의 많은 서비스들이 데이터베이스로써 MySQL을 사용합니다. 그리고 서비스 규모가 커지면 대용량 분산을 위해 샤딩을 합니다.
카카오에서 많이 사용하는 샤딩 방법으로 크게 두 가지 방식이 있습니다.
- range-based sharding
- modulus-based sharding
그러나 두 방법 모두 한계가 있습니다.
Range 방식의 한계
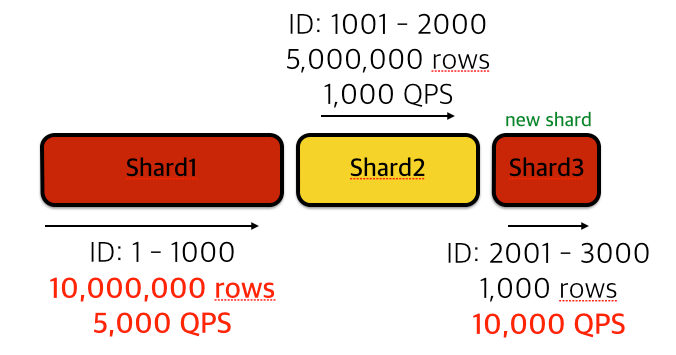
특정 ID값을 기준으로, ID 범위에 따라 샤드를 나누는 방식입니다. ID값이 증가하는 추이를 보고서 새로운 샤드 추가가 쉽다는 장점이 있습니다. 반면에 디스크 사용량이나 쿼리 처리량의 밸런스가 많이 안 맞는 경우가 발생하기도 합니다.
아래 그림과 같이 User ID 기준, Range 방식으로 샤딩을 적용한 어떤 서비스가 있다고 가정하겠습니다. 초창기 샤드는 데이터량이 아주 많고 최근에 추가된 샤드는 다른 쿼리 처리량이 매우 많습니다. 그리고 간혹 초창기 사용자들의 충성도가 높은 서비스의 경우, 초기에 추가한 샤드들도 쿼리량이 적지 않은 경우가 있습니다.
Modulus 방식의 한계
[ID값] % [샤드 개수]의 결과 값으로 샤드 위치를 결정하는 방식입니다. Range 방식에 비해 리소스 사용 밸런스가 잘 맞다고 알려져 있습니다. 그러나 이 방식은 샤드 추가가 어렵습니다.
아래 그림과 같이 3개의 샤드에서 4개의 샤드로 확장을 하려면 기존의 각 샤드마다 데이터 재배치가 필요합니다. 현재 샤드 개수의 배수로 확장하면 그나마 쉽게 샤드 추가를 할 수 있지만, 만약 현재 샤드 개수가 수십~수백이라면 적지 않은 낭비가 발생할 수도 있습니다.

그 외: Shard Scale-in/out
클라우드 서비스에서 제공하는 DB를 사용하는 서비스 경우, 간혹 이런 경우가 있습니다.
피크 타임의 수많은 UPDATE 쿼리를 버티기 위해 shard 수를 늘렸습니다. 그런데 새벽에는 DB 머신이 거의 놀고 있어서 낭비가 발생하고 있습니다. 자유롭게 shard scale in/out할 수 있는 방법은 없을까요?
이러한 기존 문제들을 해결하기 위해서는 각 샤드들의 데이터를 재분배가 필요합니다.
지금부터 ADT를 활용해 하나의 Master를 여러 샤드로 재분배하는 방법을 소개드리겠습니다.
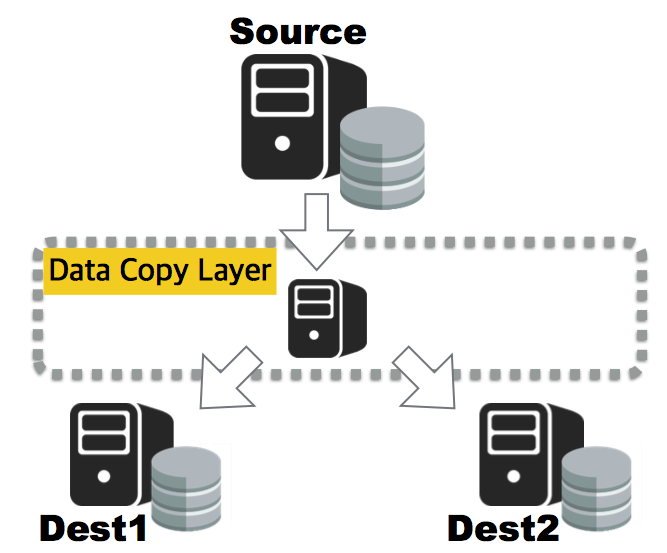
ADT Handler 구현하기
본 글에서 예제로 구현할 handler의 소스는 여기에서 확인하실 수 있습니다.
구현할 Handler의 역할
두 가지의 핸들러를 구현할 예정입니다.
- BinlogHandler: source DB의 변경 사항을 target DB에 실시간 반영
- TableCrawlHandler: binlog handler로 처리하지 못한 나머지 데이터를 처리
1. Project 생성
여기서는 Maven 기반으로 project를 생성하도록 하겠습니다. 생성 후 아래와 같이 parent를 지정합니다.
<project>
...
<parent>
<groupId>com.kakao.adt</groupId>
<artifactId>adt-handler-parent</artifactId>
<version>0.0.1-SNAPSHOT</version>
</parent>
...
</project>
2. TableCrawlHandler 구현
다음과 같이 handler interface 구현체를 만듭니다.
import com.kakao.adt.handler.MysqlCrawlProcessorHandler;
import com.kakao.adt.mysql.crawler.MysqlCrawlData;
public class TableCrawlHandler implements MysqlCrawlProcessorHandler {
@Override
public void processData(MysqlCrawlData data) throws Exception {
// TODO: 여기가 크롤링한 데이터를 처리하는 곳
}
/* 기타 constructor, method, field 등등 생략 */
}
그리고 크롤링한 각 데이터를 INSERT IGNORE를 이용하여 target DB에 복사합니다.
public void processData(MysqlCrawlData data) throws Exception {
final List<List<Object>> rowList = data.getAllRows();
final Table table = data.getTable();
for(final List<Object> row : rowList){
// 각 row를 insert ignore
insertIgnore(table, row);
}
}
public void insertIgnore(Table table, List<Object> row) throws Exception{
final int shardIndex = getShardIndex(table, row);
final String sql = getInsertIgnoreQuery(table);
// 적절한 target shard에 데이터 복사
executeUpdate(sql, shardIndex, row);
}
public int getShardIndex(Table table, List<Object> row){
// TODO: table과 row를 이용해 적절한 target shard 위치를 구합니다.
return n;
}
INSERT IGNORE로 데이터를 복사하는 이유
- 크롤링과 binlog 처리를 동시에 진행할 경우, 데이터 꼬임을 방지하기 위함
- 크롤링만 따로 실행하더라도, 아래와 같은 테이블은 단순 INSERT 시 duplicated key 에러 가능성 있음
CREATE TABLE tb (
pk int(11) NOT NULL,
uk int(11) NOT NULL,
PRIMARY KEY(pk),
UNIQUE KEY(uk)
);
3. BinlogHandler 구현
CrawlerHandler와 비슷하게, BinlogHandler용 interface 구현체를 만듭니다.
import com.kakao.adt.handler.MysqlBinlogProcessorHandler;
import com.kakao.adt.mysql.binlog.MysqlBinlogData;
public class BinlogHandler implements MysqlBinlogProcessorHandler {
@Override
public void processData(MysqlBinlogData data) throws Exception{
// TODO: Binary Log 처리하는 곳
}
/* 기타 constructor, method, field 등등 생략 */
}
각 binlog event 별로 다음과 같이 target에 적용합니다.
public void processData(MysqlBinlogData data) throws Exception{
final MysqlBinlogHandler type = data.getBinlogEventType();
final Table table = data.getTable();
final List<Object> rowBefore = getBeforeValue(data);
final List<Object> rowAfter = getAfterValue(data);
switch(type){
case WRITE_ROWS_EVENT_HANDLER:
case WRITE_ROWS_EVENT_V2_HANDLER:
replace(table, rowAfter);
break;
case DELETE_ROWS_EVENT_HANDLER:
case DELETE_ROWS_EVENT_V2_HANDLER:
deleteByPk(table, rowBefore);
break;
case UPDATE_ROWS_EVENT_HANDLER:
case UPDATE_ROWS_EVENT_V2_HANDLER:
if(/* before와 after의 PK값이 다를 경우 */){
deleteByPk(table, rowBefore);
}
replace(table, rowAfter);
break;
}
}
public void replace(Table table, List<Object> row){
final int shardIndex = getShardIndex(table, row);
final String sql = getReplcaeQuery(table);
executeUpdate(sql, shardIndex, row);
}
public void delete(Table table, List<Object> row){
final int shardIndex = getShardIndex(table, row);
final String sql = getDeleteByPkQuery(table);
executeUpdate(sql, shardIndex, getPrimaryKeyValue(table, row));
}
public int getShardIndex(Table table, List<Object> row){
// TODO: table과 row를 이용해 적절한 target shard 위치를 구합니다.
return n;
}
REPLACE를 사용하는 이유
보통 binary log를 이용하여 복구를 할 때 각 이벤트 별로 다음과 같이 DML을 사용할 것입니다.
- WRITE_EVENT
INSERT INTO ... SET @1=[after[1]], @2=[after[2]], ...;
- UPDATE_EVENT
UPDATE ... SET @1=[after[1]], ... WHERE pk=[before.pk];
- DELETE_EVENT
DELETE FROM ... WHERE pk=[before.pk]
그러나 ADT를 사용할 때는 고려할 사항들이 있습니다.
- 에러 등으로 재시작할 경우 이미 처리했던 binlog event를 replay 해야하는 경우 발생함
- ADT는 binlog event 간의 data dependency가 없다면 병렬로 처리함
- 나중에 발생한 이벤트가 먼저 처리될 가능성 있음
- 테이블 크롤링과 동시에 실행될 경우, 크롤러가 insert한 데이터와 충돌이 난다면?
이러한 문제들에 대해, 여기서는 모든 쓰기 작업을 덮어쓰기 정책으로 풀어냅니다. 위의 이벤트별 DML은 아래와 같이 변환할 수 있습니다.
WRITE_EVENT
# Normal Query
INSERT INTO ... SET @1=[after[1]], @2=[after[2]], ...;
# Overwriting 적용
# after의 값을 insert하기 위해서는 after.pk, after.uk의 값들도 삭제
DELETE FROM ... WHERE pk=[after.pk];
DELETE FROM ... WHERE uk=[after.uk];
INSERT INTO ... SET @1=[after[1]], @2=[after[2]], ...;
# Query 단순화
REPLACE INTO ... SET @1=[after[1]], @2=[after[2]], ...;
UPDATE_EVENT
# Normal Query
UPDATE ... SET @1=[after[1]], ... WHERE pk=[before.pk];
# Unrolling: 삭제 후 삽입
DELETE FROM ... WHERE pk=[before.pk];
INSERT INTO ... SET @1=[after[1]], @2=[after[2]], ...;
# Overwriting 적용: INSERT와 마찬가지로 Replace로 대체
DELETE FROM ... WHERE pk=[before.pk];
REPLACE INTO ... SET @1=[after[1]], @2=[after[2]], ...;
# PK의 변화가 없다면 REPLACE만 실행해도 됨
if( isPrimaryKeyChanged(before, after) )
DELETE FROM ... WHERE pk=[before.pk];
REPLACE INTO ... SET @1=[after[1]], @2=[after[2]], ...;
DELETE_EVENT
# DELETE 이벤트는 변화 없음
DELETE FROM ... WHERE pk=[before.pk]
Build & Run
빌드 및 실행 방법은 아래 링크를 참고하세요.
ADT 샤드 재분배 실행 전략
이번 장에서는 위에서 만든 핸들러를 이용해, 샤드 재분배를 어떻게 할 수 있는지에 대한 내용을 다룹니다. 상황에 따라 적절한 전략이 필요합니다. 아래 나열된 방법들 외에도 여러 아이디어 있으면 공유 부탁드립니다.
전략 1. 순차적으로 처리
- Table Crawler를 우선 실행
- 이 때, 시작 직전 마지막 binlog file 이름을 기록해둘 것
- 크롤링 끝난 후 Binlog Processor를 실행
- 크롤링 전 기록해두었던 파일부터 시작 *단점
- 상대적으로 오래 걸릴 수 있음
- 데이터량이 너무 많은 탓에 binlog file이 rotate 되어 삭제된 후라면…?
전략 2. 크롤링과 binlog 처리를 동시에 실행
- Binlog Processor 우선 실행
- 그 다음에 Table Crawler를 실행
INSERT IGNORE쿼리 사용
- 단점
- 데이터 충돌 가능성 있음
- 예시의 그림은 삭제된 데이터가 target에 그대로 남아있는 상황
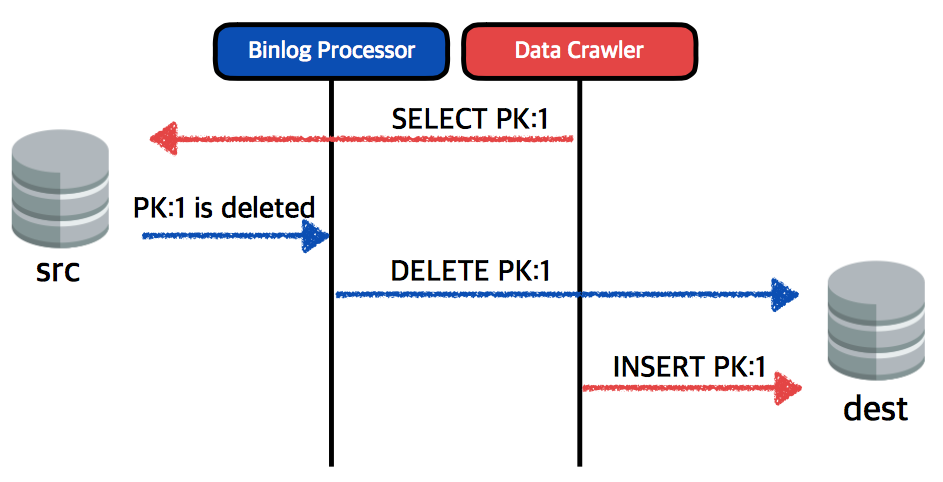
전략 2-1. Crawler SELECT할 때 Lock 사용
- Binlog Processor는 평소대로 실행
- 크롤링 시,
SELECT대신SELECT .. FOR UPDATE사용SELECT ... FOR UPDATE FOR UPDATE로 인해 락이 걸린 데이터들은 수정이 불가능하여 binlog에 남지 않음
- 단점
- Master DB 부하 증가 가능성 있음
전략 2-2. 삭제 이벤트에 대한 history 남기기
- Binlog Processor에서 삭제 이벤트 발생 시 몇 분 간 해당 내역을 어딘가에 기록을 남김
- Table Crawler 핸들러에서 INSERT 직전에 삭제 기록이 있는지 확인
- 삭제 기록이 있으면 해당 행은 INSERT 무시
- 단점
- 구현이 복잡함. 삭제 기록 캐시에 대한 락 제어 필요
전략 2-3. 2-1의 변형
- master DB에 slave 추가
- 추가한 slave를 source로 하여 2-1과 같은 방법으로 실행
- Table Cralwer가 끝나면 Binlog Processor만 원래의 master로부터 가져오도록 설정 변경 후 재시작
- 단점
- slave를 위해 추가 머신이 필요할 수 있음
- slave 추가하는데 오래 걸릴 수 있음
데이터 검증
이번 장은 카카오 내부적으로도 아직 구현은 안 된, 이론 검증 단계에 있는 부분입니다. 따라서 간단하게 소개만 드리고 다음 기회에 좀 더 자세한 내용으로 다시 찾아뵙도록 하겠습니다. 적극적인 의견/비판은 언제든 환영입니다.
위에서 구현한 핸들러가 제대로 작동하는지 확인하기 위해 단위 테스트, 통합 테스트 등도 필요하지만 실사용을 하다보면 미처 테스트에서 검증하지 못한 여러 문제가 발생하기도 합니다. 이러한 문제를 탐지하기 위해 이번 장에서는 샤드 재분배가 올바르게 진행되었는지를 검증하는 방법에 대해 지금까지 고민해온 내용들을 공유하고자 합니다.
전수 조사
데이터의 일부만 비교하여 일정 신뢰도 이상이면 문제가 없는 것으로 간주할지, 아니면 전체 데이터를 조사해야할지부터 고민이 시작되었습니다. 데이터가 너무 많아서 전수조사가 힘든 경우도 있기 때문입니다. 하지만 사용자들의 소중한 데이터를 다루는 것에 있어, 100% 외에는 있을 수 없다는 판단에 전수 조사를 택하기로 했습니다.
검증 방안 1. Source DB 데이터 변화가 없을 경우
첫번째 방법은 source DB의 데이터 변화가 없을 경우에 가능한 방법입니다. 이 방법이 가능한 상황은 서비스 중단 상태(점검 등의 이유), source DB 자체가 다른 DB의 slave이면서 동시에 replication이 중단된 상태 등이 있습니다. 후자의 경우를 예로 들면 다음과 같이 검증이 가능합니다.
- 상황 가정
- MySQL Server A, B, C1, C2가 있음
- B는 A의 slave
- ADT를 이용해 B에서 C1, C2로 데이터 재분배
- B에서 C로 Table crawler가 완전히 끝날 때까지 대기
- 크롤링 끝난 후 B에서
SLAVE STOP - B의 binlog가 C로 완전히 반영될 때까지 대기
- Binlog Processor도 더 이상 처리할 것이 없으면 B와 C의 데이터를 1:1로 모두 비교
- 전수 조사가 끝나면 Binlog Processor만 중단했던 부분부터 다시 시작
- B에서 slave 재시작
- Binlog Processor가 잘 작동하는지 확인하기 위해 주기적으로 3번부터 다시 반복
이 방법은 서비스 영향없이 데이터 검증이 가능하다는 장점입니다.
검증 방안 2. Source DB의 데이터가 실시간 변경되는 경우
source DB 데이터가 끊임없이 바뀌는 중에 검증할 수 있는 방법입니다.
- 다음과 같은 상황이라고 가정
- MySQL Server A, B1, B2가 있음
- ADT를 이용해 A의 데이터를 B1, B2로 재분배
- Table Crawler가 끝난 후, Binlog Processor만 작동 중인 상태
- A의 Binlog도 대부분 B에 반영되어 있는 상태
- A, B로부터 PK 기준 같은 범위의 값들을
SELECT하여 일치하는지 비교 - 일치하면 다음 범위로 넘어가서 2번의 방법 반복
- 처음에 0 이상 100 미만을 SELECT 했으면 그 다음에는 100 이상 200 미만, 200 이상 300 미만, …
- 일치하지 않으면 잠시 sleep
- sleep 끝난 후, 같은 범위의 PK로 2번 과정 재시도
- 재시도를 할 때마다 B값이 계속 바뀔 수 있음
- A에서 B로 데이터가 복사되고 있는 중으로 볼 수 있음
- 이런 상황은 재시도 횟수에 포함시키지 않는 것이 적절할 것으로 판단
- 재시도를 몇 회 시도했음에도 B의 데이터는 변화가 없고 일치하지 않으면 문제가 있는 것으로 간주
- 주기적으로 위의 과정들을 반복해서 검증 가능
이 방법의 특징은 실제 서비스되고 있는 데이터를 기준으로 검증을 할 수 있다는 점입니다.
위의 방법들 외 다른 아이디어, 혹은 의견 등등 언제든 환영입니다.
맺음말
지금까지 ADT를 활용하여 MySQL Shard 데이터 재분배하는 방법에 대해 알아봤습니다. 아직 카카오 내부적으로 검증 단계인 부분도 있지만 많은 분들께 도움이 되길 바랍니다. 더불어 같이 고민이나 의견을 공유하는 것도 언제든 환영입니다.^^
- 커버 이미지 출처: The Shard © Davide D’Amico
- 서버 아이콘 출처: https://icons8.com/web-app/1339/server
- 데이터베이스 아이콘 출처: http://www.seaicons.com/database-icon/
 MySQL 파티션 개요
MySQL 파티션 개요
 Mysql Join 해부(Left, Right, Outer, Inner Join)
Mysql Join 해부(Left, Right, Outer, Inner Join)