
◎ 전체 텍스트 검색
- 전체 텍스트 검색 개요
> 전체 텍스트 검색은 긴 문자로 구성된 구조화 되지 않은 텍스트 데이터(예로, 신문 기사) 등을 빠르게 검색하기 위한 부가적인 MYSQL의 기능이다.
> 전체 텍스트 검색은 저장된 텍스트의 키워드 기반의 쿼리를 위해서 빠른 인덱싱이 가능하다.
> 다음과 같은 데이터가 들어있는 테이블과 인덱스를 생각해 보자.

> 위 그림의 테이블 구조는 아마도 다음과 같을 것이다.
CREATE TABLE 신문기자_테이블 (
일자 DATE,
신문기사내용 VARCHAR(4000)
);
GO
CREATE INDEX 신문기사_인덱스 ON 신문기사_테이블(신문기사내용);
GO
> 신문기사를 계속 입력할 때마다 테이블의 크기 및 인덱스의 크기가 커질 것이다.
> 이제 신문기사를 검색해 보자.
SELECT * FROM 신문기사_테이블 WHERE 신문기사내용 = '교통 사고의 증가로 인해 오늘 ~~~';
> 위와 같이 검색하면 당연히 인덱스를 잘 사용하게 될 것이다. 그런데, 신문기사의 내용을 모두 안다면 위와 같은 검색을 할 이유가 없다. 그래서 LIKE 검색을 사용하게 될 것이다.
> 즉, 교통과 관련된 신문기사를 검색하려면 다음과 같이 사용하면 된다.
SELECT * FROM 신문기사_테이블 WHERE 신문기사내용 LIKE '교통%';
> 이렇게 검색하면 인덱스가 정려로디어 있으므로, 해당되는 내용이 인덱스를 통해서 빠르게 검색된다.
> 아마도 결과는 2019.10.19일자 기사가 검색될 것이다.
> 그런데, 문제는 2017.5.5일자 기사도 '교통'과 관련된 기사라는 점이다. 그래서 앞에 들어 있는지 중간에 들어 있든지 모든 '교통'과 관련된 내용을 검색하려면 다음과 같이 사용하면 된다.
SELECT * FROM 신문기사_테이블 WHERE 신문기사_내용 LIKE '%교통%';
> 이렇게 하면 '교통'이라는 글자가 들어간 모든 기사가 검색될 것이다. 그런데, 문제는 이렇게 되면 인덱스를 사용할 수 없다는 점이다.
> 2017.5.5일자의 '교통'은 중간에 들어 있으므로 인덱스를 사용할 방법이 없으므로 당연히 MySQL은 테이블 검색(전체 테이블을 읽는 것)을 하게 된다. 만약 10년치 기사 중에서 검색했다면 MySQL은 엄청난 부하가 발생되고 그 응답시간도 어쩌면 수 분~수 시간이 걸릴 지도 모르겠다.
> 전체 텍스트 검색은 이러한 문제를 해결해 준다. 즉, 전체 텍스트 검색은 첫 글자뿐 아니라 중간의 단어나 문장으로도 인덱스를 생성해 주기 때문에 지금과 같은 상황에서도 인덱스를 사용할 수 있어 순식간에 검색 결과를 얻을 수 있다.
- 전체 텍스트 인덱스
☞ 전체 텍스트 인덱스(FULLTEXT Index) 생성
> 전체 텍스트 인덱스는 신문기사와 같이, 텍스트로 이루어진 문자열 데이터의 내용을 가지고 생성하는 인덱스를 말한다. MySQL에서 생성한 일반적인 인덱스와는 몇 가지 차이점이 있다.
* 전체 텍스트 인덱스는 InnoDB와 MyISAM 테이블만 지원한다.
* 전체 텍스트 인덱스는 char, varchar, text의 열에만 생성이 가능하다.
* 인덱스 힌트의 사용이 일부 제한된다.
* 여러 가지 열에 FULLTEXT 인덱스를 지정할 수 있다.
> 전체 텍스트 인덱스를 생성하는 방법은 3가지가 있다. 우선 형식을 살펴보자.
형식1 :
CREATE TABLE 테이블이름 (
...
열이름 데이터형식,
... ,
FULLTEXT 인덱스이름 (열이름)
);
형식2 :
CREATE TABLE 테이블이름 (
...
열이름 데이터형식,
...
);
ALTER TABLE 테이블이름
ADD FULLTEXT (열이름);
형식3 :
CREATE TABLE 테이블이름 (
...
열이름 데이터형식,
...
);
CREATE FULLTEXT INDEX 인덱스이름
ON 테이블이름 (열이름);
☞ 전체 텍스트 인덱스(FULLTEXT Index) 삭제
> 전체 텍스트 인덱스를 삭제하는 방법은 일반 인덱스와 비슷한 방법으로 ALTER TABLE... DROP INDEX문을 사용한다.
ALTER TABLE 테이블이름
DROP INDEX FULLTEXT(열이름);
☞ 중지 단어
> 전체 텍스트 인덱스는 긴 문장에 대해서 인덱스를 생성하기 때문에 그 양이 커질 수밖에 없다. 그러므로 실제로 검색해서 무시할 만한 단어들은 아예 전체 텍스트 인덱스로 생성하지 않는 편이 좋을 것이다.
> 전체 텍스트 생성 시에 다음과 같은 경우를 생각해 보자.
![]()
> 위와 같은 문장에서 전체 텍스트 인덱스를 만든다면 '이번', '아주', '모두', '꼭'과 같은 단어로는 검색할 이유가 없으므로 제외시키는 것이 좋다. 이것이 중지 단어이다.
> MySQL 5.7은 INFORMATION_SCHEMA_FT_DEFAULT_STOPWORD 테이블에 약 36개의 중지 단어를 가지고 있다.
> 필요하다면 사용자가 별도의 테이블에 중지 단어를 추가한 후 적용시킬 수도 있다. 그리고 전체 텍스트 인덱스를 생성할 때 이 중지 단어들을 적용시키면 MySQL은 중지 단어를 제외하고 전체 텍스트 인덱스를 만들어 주게 된다. 결국, 전체 텍스트 인덱스의 크기가 최소화될 수 있다.
☞ 전체 텍스트 검색을 위한 쿼리
> 전체 텍스트 인덱스를 생성한 후에, 전체 텍스트 인덱스를 이용하기 위한 쿼리는 일반 SELECT문의 WHERE절에 MATCH() AGAINST()를 사용하면 된다.
> MySQL 도움마렝 나온 형식은 다음과 같다.
MATCH (col1, col2, ...) AGAINST (expr [search_modifier])
search_modifier:
{
IN NATURAL LANGUAGE MODE
| IN NATURAL LANGUAGE MODE WITH QUERY EXPANSION
| IN BOOLEAN MODE
| WITH QUERY EXPANSION
}
> 우선 기본적으로 기억할 사항은 MATCH() 함수는 WHERE절에서 사용한다는 점이다.
* 지연어 검색
> 특별히 옵션을 지정하지 않거니 IN NATURAL LANGUAGE MODE를 붙이면 지연어 검색을 하게 된다. 지연어 검색은 단어가 정확한 것을 검색해 준다.
> 예로 신문(newspaper)이라는 테이블의 기사(article)라는 열에 전체 텍스트 인덱스가 생성되어 있다고 가정해 보자.
> '영화'라는 단어가 들어간 기사를 찾으려면 다음과 같이 사용한다.
SELECT * FROM newspaper
WHERE MATCH(article) AGAINST('영화');
> 여기서 '영화'라는 정확한 단어만 검색되며 '영화는', '영화가', '한국영화' 등의 단어가 들어간 열은 검색되지 않는다.
> '영화' 또는 '배우'와 같이 두 단어 중 하나가 포함된 기사를 찾으려면 다음과 같이 사용한다.
SELECT * FROM newspaper
WHERE MATCH(article) AGAINST('영화 배우');
* 불린 모드 검색
> 불린 모드 검색은 단어나 문장이 정확히 일치하지 않는 것도 검색하는 것을 말하는데 IN BOOLEAN MODE 옵션을 붙여줘야 한다. 또한 불린 모드 검색은 필수인 '+', 제외하기 위한 '-', 부분 검색을 하기 위한 '*; 연산자를 지원한다.
> '영화를', '영화가', '영화는' 등의 '영화'가 앞에 들어간 모든 결과를 검색하고 싶다면 등과 같이 사용한다.
SELECT * FROM newspaper
WHERE MATCH(article) AGAINST('영화*' IN BOOLEAN MODE);
> '영화 배우' 단어가 정확히 들어있는 기사의 내용을 검색하고 싶다면 다음과 같이 사용한다.
SELECT * FROM newspaper
WHERE MATCH(article) AGAINST('영화 배우' IN BOOLEAN MODE);
> '영화 배우' 단어가 들어 있는 기사 중에서 '공포'의 내용이 꼭 들어간 결과만 검색하고 싶다면 다음과 같이 사용한다.
SELECT * FROM newspaper
WHERE MATCH(article) AGAINST('영화 배우 +공포' IN BOOLEAN MODE);
> '영화 배우' 단어가 들어 있는 기사 중에서 '남자'의 내용은 검새에서 제외하고 싶다면 다음과 같이 사용한다.
SELECT * FROM newspaper
WHERE MATCH(article) AGAINST('영화 배우 -남자' IN BOOLEAN MODE);
- 전체 텍스트 검색을 실습해 보자.
> MySQL은 기본적으로 3글자 이상만 전체 텍스트 인덱스로 생성한다. 이러한 설정을 2글자까지 전체 텍스트 인덱스가 생성되도록 시스템 변숫값을 변경하자.
> 먼저 innodb_ft_min_token_size 시스템 변수의 값을 확인해 보자. 이 값은 전체 텍스트 인덱스를 생성할 때 단어의 최소 값이다.
SHOW VARIABLES LIKE 'innodb_ft_min_token_size';
> 값이 3이 나왔을 것이다.
> 우리는 '남자' 등의 2글자 단어를 검색할 것이므로 이 값을 2로 변경해야 한다.
> Workbench를 종료한 후 명령 프롬프트를 관리자 모드로 연다.
> 다음 명령어로 MySQL의 환경 설정 파일인 my.ini 파일을 연다.
CD %PROGRAMDATA%
CD MySQL
CD "MySQL Server 5.7"
NOTEPAD my.ini
> [mysqld] 아래쪽 아무 곳이나(또는 파일의 제일 아래에) 다음 행을 추가하고 MySQL 서비스를 재시작 한다.
innodb_ft_min_token_size=2
> 다시 Workbench를 실행해서 접속한다.
> 데이터베이스 및 테이블을 생성하자.
CREATE DATABASE IF NOT EXISTS FulltextDB;
USE FulltextDB;
DROP TABLE IF EXISTS FulltextTbl;
CREATE TABLE FulltextTbl (
id int AUTO_INCREMENT PRIMARY KEY,
title VARCHAR(15) NOT NULL,
description VARCHAR(1000)
);
> 샘플 데이터를 몇 건 입력하자.
INSERT INTO FulltextTbl VALUES
(NULL, '광해, 왕이 된 남자', '왕위를 둘러싼 권력 다툼과 당정으로 혼란이 극에 달한 광해군 8년'),
(NULL, '간첩', '남한 내에 고정간첩 5만 명이 암악하고 있으며 특히 권력 핵심부에도 침투해있다.'),
(NULL, '피에타', '더 나쁜 남자가 온다! 간혹한 방법으로 돈을 뜯어내는 악마같은 남자 스토리'),
(NULL, '레지던트 이블 5', '인류 구원의 마지막 퍼즐, 이 여자가 모든 것을 끝낸다.'),
(NULL, '파괴자들', '사람은 모든 것을 파괴한다! 한 여자를 구하기 위한, 두 남자의 잔인한 액션 본능!'),
(NULL, '킹콩을 들다', '역도에 목숨을 건 시골소녀들이 만드는 기적 같은 신화'),
(NULL, '테드', '지상최대 황금찾기 프로젝트! 500년 전 사라진 황금도시를 찾아라!'),
(NULL, '타이타닉', '비극 속에 침몰한 세기의 사랑, 스크린에 되살아날 영원한 감동'),
(NULL, '8월의 크리스마스', '시한부 인생 사진사와 여자 주차 단속원과의 미묘한 사랑'),
(NULL, '늑대와 춤을', '늑대와 친해져 모닥불 아래서 함께 춤을 추는 전쟁 영웅 이야기'),
(NULL, '국가대표', '동계올림픽 유치를 위해 정식 종목인 스키점프 국가대표팀이 급조된다.'),
(NULL, '쇼생크 탈출', '그는 누명을 쓰고 쇼생크 감옥에 감금된다. 그리고 역사적인 탈출'),
(NULL, '인생은 아름다워!', '귀도는 삼촌의 호텔에서 웨이터로 일하면서 또 다시 도라를 만난다.'),
(NULL, '사운드 오브 뮤직', '수녀 지망생 마리아는 명문 트랩가의 가정교사로 들어간다.'),
(NULL, '매트릭스', '2199년. 인공 두뇌를 가진 컴퓨터가 지배하는 세계.');
> 아직 전체 텍스트 인덱스를 만들지 않았다. 이 상태에서 '남자'라는 단어를 검색해 보자.
SELECT * FROM FulltextTbl WHERE description LIKE '%남자%';
> 결과는 잘 나왔다. 실행 계획을 확인해보자.
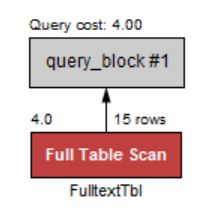
> 실행 계획을 보면 전체 테이블 검색을 하였다. 지금 데이터가 몇 건 되지 않아서 문제가 없지만, 대용량의 데이터라면 MySQL에 상당한 부하가 생길 것이다.
> 전체 텍스트 인덱스를 생성하고 인덱스 정보를 확인해 보자.
CREATE FULLTEXT INDEX idx_description ON fulltextTbl(description);
SHOW INDEX FROM fulltextTbl;
> description열에 생성된 인덱스의 Index_typedl 'FULLTEXT'인 것을 확인할 수 있다.
> 앞과 동일하게 '남자'가 들어간 행을 검색해 보자.
SELECT * FROM FulltextTbl WHERE MATCH(description) AGAINST('남자*' IN BOOLEAN MODE);
> 결과는 동일하게 나왔다. 실행 계획을 확인해 보자.
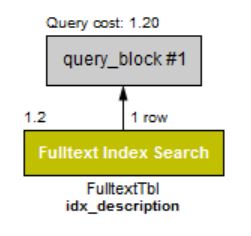
> 실행 계획을 보면 전체 텍스트 인덱스 검색을 하였다. 인덱스를 사용했으므로 앞에서 전체 테이블 검색을 한 성능과는 비교도 되지 않을 정도로 빠른 결과가 나왔을 것이다.
> '남자' 또는 '여자'가 들어간 행을 검색해 보자. 또한 매치되는 점수도 출력해 보자.
SELECT * FROM FulltextTbl where title='8월의 크리스마스';
SELECT *, MATCH(description) AGAINST('남자* 여자*' IN BOOLEAN MODE) AS 점수
FROM FulltextTbl WHERE MATCH(description) AGAINST('남자* 여자*' IN BOOLEAN MODE);

> id와 점수를 보면 점수가 높은 순서로 정렬되어서 출력된 것을 확인할 수 있다. id가 5인 행은 '남자'와 '여자'가 모두 나와서 높은 점수가 나왔고, 나머지는 한 번만 나와서 점수가 같다.
> 주의할 점은 동일한 것이 여러 개 나와도 1개만 나온 것으로 처리된다. id가 3인 행은 '남자'가 두 번 나오지만 한 번으로 처리되었다.
> '남자'와 '여자'가 둘다 들어 있는 영화를 출력해 보자. +연산자를 사용하면 필수로 들어 있어야 한다는 의미다.
SELECT * FROM FulltextTbl
WHERE MATCH(description) AGAINST('+남자* +여자*' IN BOOLEAN MODE);
> 결과는 '파괴자들' 영화가 나왔을 것이다.
> '남자'가 들어 있는 영화 중에서 '여자'가 들어 있는 영화를 제외시켜 보자. - 연산자는 제외시킨다는 의미다.
SELECT * FROM FulltextTbl
WHERE MATCH(description) AGAINST('남자* -여자*' IN BOOLEAN MODE);
> 결과는 '피에타' 영화가 나왔을 것이다.
> 이번에는 다음 쿼리문으로 전체 텍스트 인덱스로 만들어진 단어를 확인해 보자.
SET GLOBAL innodb_ft_aux_table = 'fulltextdb/fulltexttbl';
SELECT word, doc_count, doc_id, position
FROM INFORMATION_SCHEMA.INNODB_FT_INDEX_TABLE;
> 'word'는 인덱스가 생성된 단어나 문구를 말하고 'doc_count'는 몇 번이나 나왔는지를 말한다.
> 그런데, 자세히 살펴보면 '그', '그리고', '극에' 등의 단어도 인덱스로 생성되어 있다. 아마도 검색할 때 이런 단어로 검색하지는 않을 것이므로 전체 텍스트 인덱스로 생성될 필요가 없는 단어들이다. 이것들 때문에 전체 텍스트 인덱스가 쓸데없이 커지게 될 것이다.
> 우선, 제일 아래로 드래그해서 전체 텍스트 인덱스가 몇 단어 생성되었는지 기억해 놓자. 나는 80개 생성되었다.
> 전체 텍스트 인덱스의 크기를 줄이기 위해서 '중지 단어'를 추가해 보자. 먼저 앞에서 생성한 전체 텍스트 인덱스를 삭제하자.
DROP INDEX idx_description ON FulltextTbl;
> 사용자가 추가할 중지 단어를 저장할 테이블을 만들자. 주의할 점은 테이블 이름은 아무거나 상관 없으나 열 이름은 value와 VARCHAR 형태로 지정해야 한다.
CREATE TABLE user_stopword (value VARCHAR(30));
> 중지 단어를 입력하자. 지금의 예에서는 1개만 추가했다.
INSERT INTO user_stopword VALUES ('그리고');
> 중지 단어용 테이블을 시스템 변수 innodb_ft_server_stopword_table에 설정하자. 주의할 점은 홀따옴표 안의 DB 이름과 테이블 이름은 모두 소문자로 써야 한다.
SET GLOBAL innodb_ft_server_stopword_table = 'fulltextdb/user_stopword';
SHOW GLOBAL VARIABLES LIKE 'innodb_ft_server_stopword_table';
> 다시 전체 텍스트의 인덱스를 만들자.
CREATE FULLTEXT INDEX idx_description ON FulltextTbl(description);
> 다시 전체 텍스트의 인덱스에 생성된 단어를 확인해 보자.
SELECT word, doc_count, doc_id, position
FROM INFORMATION_SCHEMA.INNODB_FT_INDEX_TABLE;
> 1개가 제외된 79개가 생성되었으며 제외된 단어는 보이지 않는다. 즉, 중지 단어를 제외하고 전체 텍스트 인덱스가 생성된 것이다.
◎ 파티션
- 파티션 개요와 실습
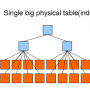
> 파티션은 대량의 테이블을 물리적으로 여러 개의 테이블로 쪼개는 것을 말한다. 예로 수십억 건의 테이블에 쿼리를 수행할 떄, 비록 인덱스를 사용한다고 해도 테이블의 대용량으로 인해서 MySQL에 상당한 부담이 될 수밖에 없다.
> 이럴 때, 하나의 테이블이 10개의 파티션으로 나눠서 저장되어 있다면 경우에 따라서는 그 부담이 1/10로 줄어들 수도 있다.
※물론 무조건 파티션으로 나뉜다고 효율적이 되는 것은 아니며, 데이터의 분포 특성이나 자주 사용되는 쿼리문이 무엇인지에 따라서 효율에 큰 차이가 있을 수 있다.
> 테이블의 행 데이터가 무척 많은 대용량의 데이터베이스를 생각해 보면, INSERT, UPDATE 등의 작업이 갈수록 느려질 수밖에 없다. 이럴 경우 파티션으로 나누면 시스템 성능에 큰 도움이 될 것이다.
> 테이블을 분할할 때는 테이블의 범위에 따라서 서로 다른 파티션에 저장하는 것이 가장 보편적이다.
> 예로 10년간의 데이터가 저장된 테이블이라면 아마도 과거의 데이터들은 주로 조회만 할 뿐 거의 변경이 되지 않을 것이다. 그러므로 작년 이전의 데이터와 올해의 데이터를 서로 다른 파티션에 저장한다면 효과적일 수 있다.
> 또 다른 예로는 각 월별로 업데이트가 잦은 대용량 데이터라면 각 월별로 파티션 테이블을 구성할 수도 있다.
※ MySQL은 최대 1,024개의 파티션을 지원하는데, 파티션을 나누면 물리적으로는 파일이 분리된다. 그렇기 때문에 파티션 테이블은 파일이 동시에 여러 개 열린다. MySQL은 동시에 열 수 있는 파일의 개수가 시스템 변수 open_file_limit에 저장되어 있다. 그러므로 파티션을 많이 나눌 경우에는 시스템 변수 open_file_limit 값을 크게 변경시켜줄 필요가 있다.
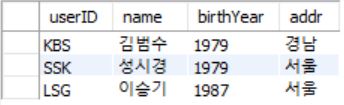
> 아래 그림은 sqlDB의 회원 테이블을 출생년도별로 3개의 파티션으로 구분하기 위한 개념도이다.
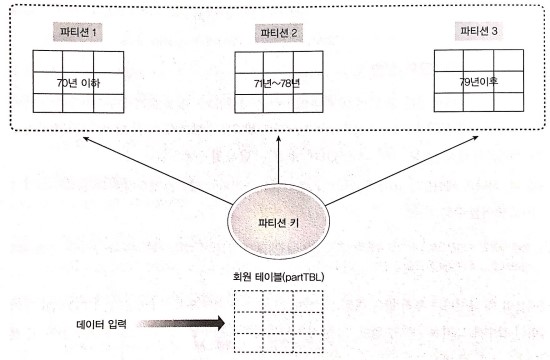
> 테이블을 생성할 때 파티션 키를 함께 지정한다. 그러면 데이터를 입력할 때 지정한 파티션 키에 의해서 데이터가 각각의 파티션에 입력되는 개념이다.
> 물론 사용자는 파티션이 몇 개이든 관계 없이 테이블 하나에만 접근한다고 생각하면 된다. 즉, 파티션을 나눴든 그렇지 않든 MySQL의 내부적인 문제일 뿐 사용자는 신경쓰지 않아도 된다.
- 파티션을 구현하자. 테이블은 sqlDB의 회원 테이블과 동일한 데이터를 입력하는 것으로 하겠다.
> 저장해 놓은 sqlDB.sqp을 이용해서 sqlDB 데이터베이스를 초기화 시키자.
> 위의 파티션 개념도 그림과 같은 파티션으로 분리되는 테이블을 정의하자. 파티션은 다음과 같은 표로 구성할 수 있다.

CREATE DATABASE IF NOT EXISTS partDB;
USE partDB;
DROP TABLE IF EXISTS partTbl;
CREATE TABLE partTbl(
userID CHAR(8) NOT NULL,
name VARCHAR(10) NOT NULL,
birthYear INT NOT NULL,
addr CHAR(2) NOT NULL)
PARTITION BY RANGE(birthYear) (
PARTITION part1 VALUES LESS THAN (1970),
PARTITION part2 VALUES LESS THAN (1978),
PARTITION part3 VALUES LESS THAN MAXVALUE
);
> 우선 파티션 테이블에는 Primary Key를 지정하면 안된다.
> 파티션 테이블을 지정하는 문법은 테이블의 정의가 끝나는 부분해서 PARTITION BY RANGE(열이름)로 지정한다. 그러면 열 이름의 값에 의해서 지정된 파티션으로 데이터가 지정된다.
> 첫 번째 파티션에는 1970년 이하 출생인 회원이 저장되고, 두 번째는 1971년부터 1978년까지 출생된 회원이 저장된다. 세 번째는 1979 이후에 출생한 회원이 저장된다.
> MAXVALUE는 1978 초과(=1979 이상)의 모든 값을 의미한다.
※ Primary Key로 지정하면 그 열로 정렬이 되기 때문에 파티션으로 하면 안된다. 만약 Primary Key로 지정하려면 파티션에서 사용되는 열도 함께 Primary Key로 지정해야 한다. 이 예는 userID와 birthYear를 함께 Primary Key로 지정해야 한다.
또, RANGE(열 이름) 옵션은 범위를 지정하는 레인지 파티션을 만든다. 주의할 점은 열 이름은 숫자형 데이터여야 하며 문자형은 오면 안된다는 것이다.
> 회원 테이블의 데이터를 입력한다. 회원 테이블을 모두 입력하려니 좀 귀찮다. 그래서 sqlDB에 동일한 데이터가 있으니 그 데이터를 한꺼번에 가져와서 입력하자. 입력이 되는 동시에 파티션 키에 의해서 데이터가 각 파티션으로 나뉘어진다.
INSERT INTO partTbl
SELECT userID, name, birthYear, addr FROM sqlDB.userTbl;
> 입력한 데이터를 확인한다.
SELECT * FROM partTbl;
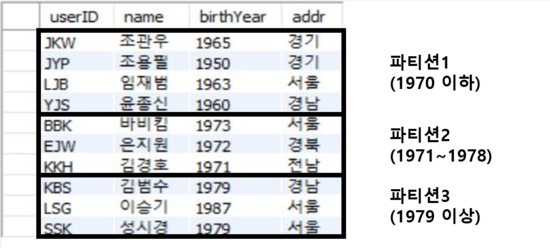
> 데이터가 출력된 결과를 보면 part1, part2, part3 파티션 순서로 조회된 것을 예상할 수 있다.
> 파티션을 확인해 보자. INFORMATION_SCHEMA 데이터베이스의 PARTITIONS 테이블에 관련 정보가 들어 있다.
SELECT TABLE_SCHEMA, TABLE_NAME, PARTITION_NAME, PARTITION_ORDINAL_POSITION, TABLE_ROWS
FROM INFORMATION_SCHEMA.PARTITIONS
WHERE TABLE_NAME = 'partTbl';

> 결과를 보면 파티션 이름, 파티션의 일련번호, 파티션에 저장된 행 개수 등을 알 수 있다. 앞에서 예상한 결과와 동일한 행 개수를 가지고 있다.
> 범위를 지정해서 조회해 보자. 1965년 이전에 출생한 회원을 조회해 보자.
SELECT * FROM partTbl WHERE birthYear < 1965;
> 결과는 3명이 나왔을 것이다. 파티션1만 조회해서 결과를 가져왔을 것이다. 실제 대용량 데이터였다면 파티션2와 파티션3은 아예 접근하지도 않았으므로 상당히 효율적인 조회를 한 것이다.
> 어느 파티션을 사용했는지 확인하려면 쿼리문 앞에 EXPLAIN PARTITIONS문을 붙이면 된다.
EXPLAIN PARTITIONS
SELECT * FROM partTbl WHERE birthYear < 1965;
![]()
> 파티션을 관리하는 방법을 익히자. 만약 파티션3을 1979~1985(파티션3)와 1986 이후(파티션4)로 분리하고자 한다면 ALTER TABLE...REORGANIZE PARTITION문을 사용하면 된다. 또한 파티션을 재구성하기 위해서 OPTIMIZE TABLE문을 수행해줘야 한다.
ALTER TABLE partTbl
REORGANIZE PARTITION part3 INTO (
PARTITION part3 VALUES LESS THAN (1985),
PARTITION part4 VALUES LESS THAN MAXVALUE
);
OPTIMIZE TABLE partTbl;
※ 파티션을 추가하기 위해서는 ALTER TABLE...ADD PARTITION을 사용해야 한다. 그런데 MAXVALUE로 설정되어 있는 파티션 테이블에는 파티션을 추가할 수가 없다. 이런 경우에는 지금과 같이 파티션을 분리하는 방식으로 추가해야 한다.
> 다시 INFORMATION_SCHEMA 데이터베이스의 PARTITIONS 테이블을 조회해 보자.

> 기존의 파티션3에 있던 테이블 3개가 파티션3에 2개, 파티션4에 1개로 자동으로 분리되어다.
> 이번에는 파티션을 합쳐보자. 1970 이하인 파티션1과 1971~1978 파티션2를 합쳐서 1978 이하(파티션12)로 합쳐보자.
ALTER TABLE partTbl
REORGANIZE PARTITION part1, part2 INTO (
PARTITION part12 VALUES LESS THAN (1978)
);
OPTIMIZE TABLE partTbl;
> 다시 INFORMATION_SCHEMA 데이터베이스의 PARTITIONS 테이블을 조회해 보자.

> 합쳐진 파티션12에 기존 파티션1의 데이터 4개와 파티션2의 데이터 3개가 합쳐진 데이터 7개가 들어간 것이 확인된다.
> 파티션12를 삭제해 보자.
ALTER TABLE partTbl DROP PARTITION part12;
OPTIMIZE TABLE partTbl;
> 데이터를 조회해 보자.
SELECT * FROM partTbl;
> 파티션12에 있던 데이터 7건은 파티션과 함께 삭제되었다. 즉, 파티션을 삭제하면 그 파티션의 데이터도 함께 삭제되므로 주의해야 한다.
※ 대량의 데이터를 삭제할 때 파티션을 삭제하면 상당히 빨리 삭제된다. 파티션의 데이터를 모두 삭제할 때는 DELETE문보다는 파티션 자체를 삭제하는 것이 효율적이다.
- 파티션의 정리
> 파티션은 대량의 테이블을 물리적으로 분리하기 때문에 상당히 효율적일 수 있지만, 몇 가지 제한 사항도 고려해야 한다. 파티션에서 부가적으로 기억해야 할 내용은 다음과 같다.
* 파티션 테이블에 외래 키를 설정할 수 없다. 그러므로 단독으로 사용되는 테이블에만 파티션을 설정할 수 있다.
* 스토어드 프로시저, 스토어드 함수, 사용자 변수 등을 파티션 함수나 식에 사용할 수 없다.
* 임시 테이블은 파티션 기능을 사용할 수 없다.
* 파티션 키에는 일부 함수만 사용할 수 있다.
* 파티션 개수는 최대 1,024개까지 지원된다.
* 레인지 파티션은 숫자형의 연속된 범위를 사용하고, 리스트 파티션은 숫자형 또는 문자형의 연속되지 않은 하나 하나씩의 파티션 키 값을 지정한다.
* 리스트 파티션에는 MAXVALUE를 사용할 수 없다. 즉, 모든 경우의 파티션 키 값을 지정해야 한다
 전체 텍스트 검색과 파티션
전체 텍스트 검색과 파티션
 MySQL 파티션 개요
MySQL 파티션 개요